L’intelligence artificielle fait référence à des technologies capables de simuler (ou d’imiter) une activité humaine. Derrière cette métaphore, on retrouve une panoplie de systèmes dont le point commun est de traiter des données et d’en extraire une signification.
Les systèmes experts furent les premiers à être expérimentés. Il s’agit de programmes de raisonnement fonctionnant par inférence, et s’appuyant sur une base de connaissances. Les systèmes de planification sont notamment utilisés dans le monde de la robotique. Ils font référence à des algorithmes capables de planifier des séquences d’actions à exécuter. Mais lorsque l’on parle d’IA aujourd’hui, on pense davantage aux algorithmes d’apprentissage automatique (machine learning, deep learning), qui permettent d’améliorer les performances d’une tâche définie en se basant sur une expérience nourrie par des données.
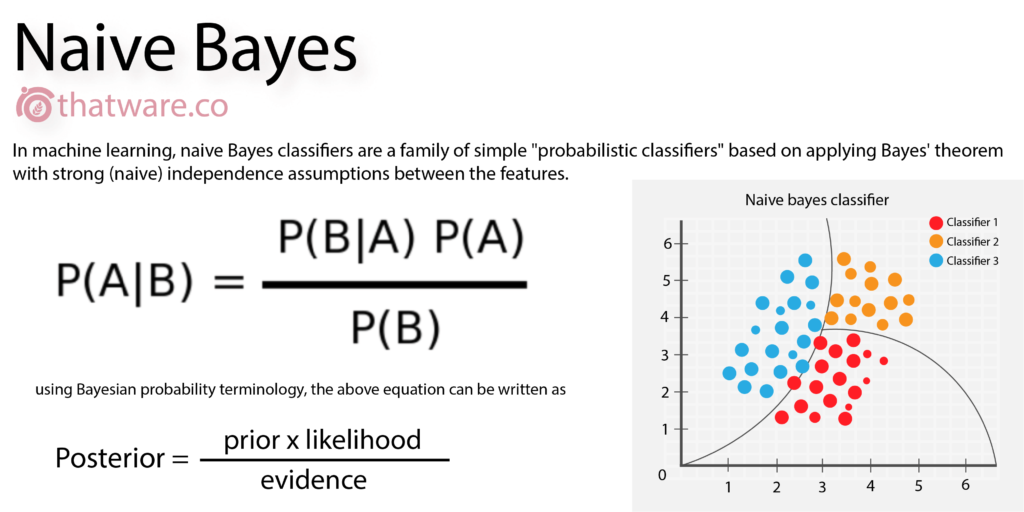
Les algorithmes de machine learning peuvent être répartis en quatre catégories. En premier lieu, l’apprentissage supervisé cherche à établir une représentation compacte d’association entre des entrants et des extrants, par l’intermédiaire d’une fonction de prédiction. Il fait notamment référence à des algorithmes de régression linéaire, qui permettent de modéliser simplement des relations complexes, et à des arbres de décision, dont les faiblesses sont de nécessiter beaucoup de données et d’être parfois difficiles à interpréter. L’apprentissage non supervisé est une technique de deep learning, incluant des algorithmes traitant avec des données non labellisées (ou non annotées).
Ils permettent d’analyser un grand nombre de données, de découvrir des connaissances renfermées dans ces données, ainsi que d’établir des prédictions ou des classifications. L’apprentissage semi-supervisé construit des modèles à partir de données labellisées et non labelllisées, par exemple pour établir des classements ou générer du texte de manière automatique, tandis que l’apprentissage par renforcement s’appuie sur des interprétations du système en fonction des récompenses et des punitions qu’il reçoit. Un tel type d’algorithme est notamment utilisé pour les jeux où une machine affronte un humain (et finit souvent par gagner). Tous ces algorithmes nécessitent des machines puissantes (nos ordinateurs portables ne font pas le poids), aini que des données de qualité pour pouvoir fonctionner. Mais que se passe-t-il lorsque ces données sont biaisées ? Fort logiquement, elles donnent lieu à des résultats qui sont eux aussi biaisés.
Bien que nos images mentales de l’intelligence artificielle aient sans doute été façonnées par de nombreuses fictions – encourageant à voir celle-ci comme une amie sympa ou comme la pire ennemie de l’humanité –, ses représentations sont quotidiennement devant nous… sans que nous en soyons forcément conscients. Les technologies de l’IA et de la robotique sont utilisées pour établir des diagnostics médicaux, prédire les comportements des consommateurs ou cibler certains groupes avec des publicités, modéliser l’évolution d’une pandémie, accepter ou refuser l’octroi d’un prêt par une institution bancaire, recruter un candidat, recommander des actualités, déterminer le montant d’une police d’assurance, jouer le rôle d’assistant personnel, prendre en charge les tâches répétitives d’un travailleur humain, piloter des voitures de manière autonome,… Leurs applications commerciales sont nombreuses : au-delà des expériences menées en laboratoires, l’IA c’est aussi – et surtout – une affaire de business. Ce n’est pas pour autant qu’il faut y voir nécessairement un mal. Les bénéfices de ces technologies sont nombreux pour l’individu et la société. Mais pour qu’il y ait bénéfices, il faut en évaluer les risques. Les débats portant sur l’éthique sont sains et nécessaires pour encourager des développements et usages responsables de l’IA.
Le champ de l’éthique se décline en trois écoles dont les fondements sont différents, mais qui peuvent être envisagés de manière complémentaire dans le contexte de l’IA. L’approche conséquentialiste défend l’idée que la valeur d’une action dépend de ses conséquences (une action est juste si ses conséquences sont bonnes) ; l’approche déontologique place le curseur sur le devoir sous-tendant une action ; et l’approche de la vertu met en avant la moralité. Bien que l’éthique et le droit soient perçus comme distincts, certaines règles juridiques peuvent être envisagées sous le prisme éthique. Toutefois, l’éthique a ceci de particulier qu’elle n’est pas contraignante.
Transparence vs explicabilité
En février 2020, la Commission européenne publiait un livre blanc sur l’IA dans lequel elle souligne les changements attendus : amélioration des soins de santé, adaptation de l’agriculture au changement climatique, augmentation de l’efficacité des systèmes de productions… Mais ceci, dit-elle, s’accompagne aussi de risques potentiels « tels que l’opacité de la prise de décisions, la discrimination fondée sur le sexe ou sur d’autres motifs, l’intrusion dans nos vies privées ou encore l’utilisation à des fins criminelles ». Ceci illustre le fait que les enjeux éthiques d’un secteur ne sont pas forcément ceux d’un autre. Mais dans le débat éthique, l’en d’entre eux se répète de manière transversale: celui de la transparence.
Pour autant, celle-ci est-elle envisageable, possible, dans un contexte où le code est ce qui donne de la valeur pour son propriétaire ? Un algorithme de machine learning peut être utilisé pour entraîner un modèle et améliorer ses performances. Mais celui qui le lance ne comprend pas forcément le parcours de cet algorithme et cela d’autant plus que de petites modifications dans un jeu de données peuvent donner lieu à de grandes différences dans les résultats. Certains algorithmes, comme ceux utilisés dans le deep learning, sont d’ailleurs de véritables boîtes noires. Quant à l’utilisateur lambda, est-il prêt à se lancer dans le déchiffrage d’un algorithme et dans la comprehension avancée de méthodes de calculs et de probabilités ? Dans ce contexte, le principe d’explicabilité semble le meilleur compromis. Il consiste à être capable d’expliquer pourquoi un système est arrivé à un résultat donné. L’explicabilité a ceci comme avantage qu’elle permet de faire sens, de participer à la démystification du système.