Trois sociétés actives dans la génération automatique de textes en langue naturelle (GAT) ont été étudiées dans le mémoire @MaSTICulb. Parmi celles-ci, la société française Syllabs et sa solution Data2Content. Première partie de cette étude de cas, axée sur la collaboration avec Le Monde lors des élections départementales et sur la question de la qualité des données.
Lors du second tour des élections départementales, le binôme du Parti Socialiste composé de M. KANNER Patrick et de Mme STANIEC-WAVRANT Marie-Christine est ressorti vainqueur du duel, qui a eu lieu dans le canton de Lille-5 (Nord), avec 59,65% des suffrages exprimés (soit 19,9% des inscrits). M. KINGET François et Mme MAHIEU Isabelle (Union de la Droite) ont perdu avec un résultat de 40,35% des suffrages exprimés. Dans ce canton, 63,77% des inscrits se sont abstenus.
Ce texte a été produit par la solution de génération automatique Data2Content, commercialisée par la société française Syllabs, à l’occasion des élections départementales françaises de mars 2015. Pour la première fois, un média de langue française faisait appel aux technologies de la génération automatique de textes en langue naturelle (GAT) pour produire un important volume de textes – plus de 30.000 – à partir de données brutes. Il s’agit d’une application « data-to-text » de la GAT, qui désigne les systèmes informatiques capables de produire des textes dans une langue compréhensible par un humain.

Syllabs, start-up parisienne fondée en 2006, s’est spécialisée dans l’analyse sémantique et le développement d’offres sur mesure pour les médias et éditeurs de contenus pour valoriser leur archives, effectuer des revues de presse ; ou encore détecter, collecter, analyser et lier des news en ligne. Dans ce cadre, Syllabs a travaillé avec Les Echos, Slate.fr, La Tribune et France Télévisions. Une autre de ses activités consiste en la commercialisation de la solution de génération automatique Data2Content, dans un premier temps utilisée pour générer des contenus dans le domaine de l’e-tourisme et de l’e-commerce.
Data2Content consiste, explique Helena Blancafort, co-fondatrice de Syllabs, en « un moteur de rédaction qui transforme de l’information structurée en textes« . Un paramétrage des modules qui composent le logiciel – par un ingénieur linguiste – a lieu avant chaque type de génération. « Ce n’est donc pas si automatique que ça et le système est moins lourd qu’un système traditionnel« , souligne-t-elle. « Data2Content a été pensé pour être un outil industriel, qui produit des textes rapidement. Le langage de programmation est un langage de programmation propre qui est un peu différent d’un système traditionnel ».
La première version du logiciel a été développée sur une période de six mois. Une seconde version, « plus souple, avec plus de fonctions » a elle aussi nécessité six mois de développement. Une troisième version, ayant pour objectif l’extension des fonctionnalités du logiciel, est en cours et il s’agit également « d’un travail de six mois ».
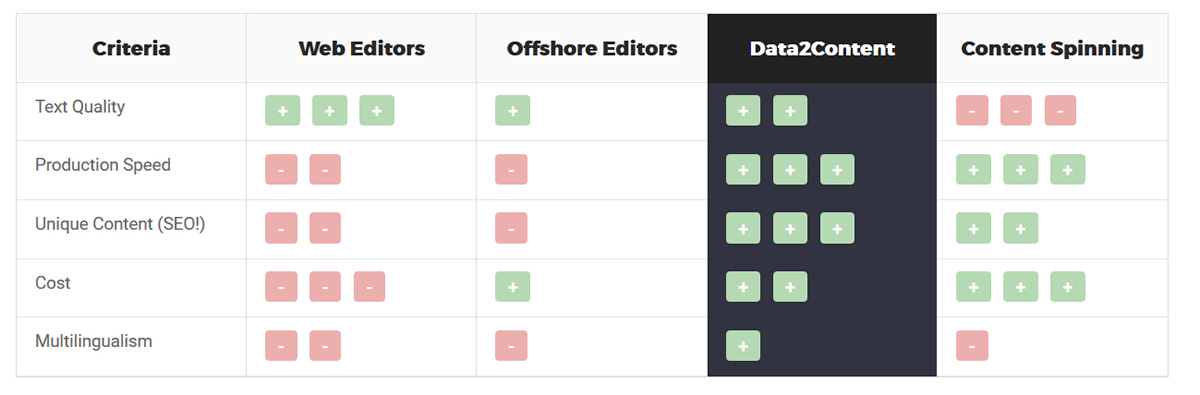
Le logiciel est capable de traiter plusieurs langues – français, anglais, espagnol – et chacune d’entre elle dispose d’un module spécifique. Sur le site de Data2Content, les points forts et les points faibles de différentes approches rédactionnelles sont comparés avec le logiciel : rédaction web, rédaction offshore et content spinning. Le concept de rédaction offshore désigne la délocalisation d’activités de rédaction dans un pays où les rémunérations sont plus basses que dans le pays d’origine. Celui de content spinning désigne une méthode permettant de générer des textes de manière aléatoire à partir de mêmes lemmes (réécriture automatique). Cette technique est utilisée dans le cadre d’activités de référencement . Les avantages de Data2Content tiendraient dans sa qualité d’écriture, sa rapidité de création, sa capacité à générer du contenu unique (des variations peuvent être introduites à tous les niveaux du texte), son prix (dès lors qu’un nombre suffisant de textes doit être créé), et son multilinguisme.
Les performances du système dépendent des données en entrée, indique Helena Blancafort. « Plus il y en a, plus il sera facile de produire des textes longs. La production est proportionnelle à la longueur des textes. On avait calculé que le système peut produire 10.000 textes courant de 100 mots en une heure. Après, on peut paralléliser les machines et monter en puissance. Sur le plan du volume de données traitées, d’un point de vue technique, il n’y a pas de limites ».
Lors des élections départementales en France, le 22 mars 2015, deux heures trente après la fermeture des bureaux de vote, 10% des communes et cantons avaient été traités par le robot, pour un volume de 4.000 textes écrits, pour le site web du journal Le Monde. Un total de 36.000 textes a été produit ce soir-là. Luc Bronner, directeur adjoint des rédactions du Monde, justifie la mise en place de ce dispositif par l’expérimentation « de nouveaux outils susceptibles d’apporter un nouveau service à nos lecteurs (. . . ) Admettons également que ces textes sont plus facilement repérables par les moteurs de recherche : ils permettent de donner plus de chance à des lecteurs éloignés (. . . ) de nous retrouver – un enjeu clé désormais pour l’ensemble des médias en France et dans le monde ».
Qualité des données
Le format des données avec lesquelles travaille le système est du JSON, pour l’essentiel. « On travaille avec du aussi avec du XML et du CSV, mais pourquoi pas d’autres formats. Pour nous le plus simple, c’est JSON car le XML est plus lourd, plus verbeux. Cela nécessite parfois des procédures de conversion« , explique Helena Blancafort.
Le domaine d’application journalistique induit, selon elle, des contraintes de style. « Si on travaille pour un journal donné, il faut s’adapter à son style. La variabilité SEO (optimisation pour les moteurs de recherche, ndlr) va être moins importante car ce qui est important ici, c’est de coller un style. Ensuite, il y a la mise en contexte. Lorsque l’on travaille sur un texte journalistique, il faut penser à faire un lien avec l’actualité, avec les connaissances. Par exemple, si je traite des élections municipales, je vais présenter les résultats des élections par commune. Mais si je veux rédiger un texte qui ait du sens, je vais faire des liens avec les élections précédentes. Pour cela, il me faut des informations socio-économiques sur la commune. Il faut donc travailler avec plusieurs bases de données, parmi lesquelles des bases de données open data. Le gouvernement français met à disposition pas mal de données socio-économiques. On peut utiliser ces données-là, mais il faut qu’elles soient à jour : ce qui n’est pas toujours le cas ».
Helena Blancafort estime que les données sont souvent problématiques. « Il faut que l’on fasse un nettoyage, parfois des vérifications manuelles. En même temps on ne peut pas tout vérifier. Avec l’open data public, la mise à jour des données est un réel problème. Par exemple, on peut récupérer un fichier avec tous les maires élus en 2014. Si je veux écrire un texte sur le sujet aujourd’hui, en utilisant ces données, je risque de ne pas avoir des données actualisées : entre 2014 et aujourd’hui, certains maires sont peut-être décédés ou ont démissionné de leur fonction. Nous ne pouvons pas nous occuper de ces mises à jour ».
Seconde partie : Pocessus éditorial et un appui au travail journalistique




