La génération automatique de textes en langue naturelle (GAT) désigne les systèmes informatiques capables de produire des textes dans une langue compréhensible par un humain.

Pour ce faire, ces systèmes utilisent ”les connaissances du langage et d’un domaine d’application pour produire automatiquement des rapports, des documents, (…) des messages d’aide et tout autre type de texte”, expliquent Dale et Reiter[1]. Pour ces chercheurs, il s’agit d’un sous-champ de l’intelligence artificielle et de la linguistique computationnelle. La GAT peut, en effet, dans certains cas, faire appel à des systèmes experts (capables de reproduire des processus cognitifs d’un expert dans un domaine donné[2]), comme c’est le cas pour les sociétés de génération américaines Narrative Science et Automated Insights.
Mais la génération automatique de textes en langue naturelle est avant tout un sous-domaine du traitement automatique de la langue (TAL), ”souvent caractérisé comme l’étude de la conversion automatique de représentations non linguistiques (par exemple, des bases de données ou d’autres sources de connaissances), en texte cohérent en langage naturel”[3].
A noter que les textes en langue naturelle sont présents dans tous les systèmes d’information. Ils le sont d’ailleurs depuis les débuts de l’informatique, relève Danlos : ”Depuis qu’ils existent, les ordinateurs produisent des textes en langue naturelle. Exemple : ’votre imprimante n’a plus de papier.’ Mais ce type de message, qui ne s’affiche qu’en cas de besoin après une commande d’impression, est pré-enregistré et ne nécessite aucune ’intelligence’”[4].
Text-to-text et data-to-text
Les chercheurs répartissent les systèmes de GAT en deux grandes catégories : les systèmes texte-vers-texte (text-to-text) et les systèmes données-vers-texte (data-to-text). Ces seconds systèmes sont mis en œuvre dans un contexte journalistique.
Danlos voit de nombreux avantages dans la GAT : réutilisabilité et maintenance (tout ajout ou modification s’opère dans la base de données), recherche d’informations (dans la base de données), flexibilité et interactivité (un ordinateur peut proposer différentes phrases à partir d’une même représentation abstraite), multilinguisme (production à partir d’une même base de données, ajout de langue peu coûteux), personnalisation et langues contrôlées (un système paramétrable permet des ajustements aux besoins et circonstances)[5].
Un processus de choix
La génération automatique de textes en langue naturelle est une question de choix. Quels contenus inclure ? Comment les organiser, les structurer, les styliser ? Quels mots utiliser ? Dans quelles constructions syntaxiques ? Les systèmes de GAT traitent des informations non linguistiques, qu’ils transforment en textes compréhensibles par un être humain. Pour y parvenir, la connaissance du domaine d’application est un préalable car c’est de lui que dépend la qualité des textes et leur compréhension[6]. La connaissance doit non seulement porter sur le domaine mais aussi sur la connaissance que le lecteur a du domaine, et la connaissance de ce que le lecteur veut savoir, relève Dalianis[7]. Il estime également que les processus mis en oeuvre sont semblables à ceux observés chez un auteur: ”décider quelles informations transmettre, planifier et organiser cette information pour construire une structure de discours cohérent, décider la structure de la phrase et son champ d’application, choisir les constructions syntaxiques et les mots à utiliser”.
Les systèmes de GAT reçoivent en entrée (input) des données non linguistiques et produisent en sortie (output), un texte cohérent. La production de textes s’appuie sur un système de représentations informatisées dont les énoncés doivent, indique Danlos, ”être grammaticalement corrects, sémantiquement cohérents et pragmatiquement pertinents”[8]. Ces applications portent nécessairement sur un domaine donné (constat d’accident, bulletin météo) et dans un genre donné (récit, manuel, dialogue), souligne Danlos. Qui indique que les systèmes de génération automatique de texte doivent ”satisfaire deux exigences : 1) indiquer à l’utilisateur l’information qu’il désire, 2) offrir une formulation de ces informations dans une langue soutenue”. Ces deux exigences, poursuit-elle, correspondent à une modélisation du processus de réponse : un module de raisonnement ou un système expert traite la question ”Quoi dire ?”, et un module de génération automatique traite la question ”Comment le dire ? ».
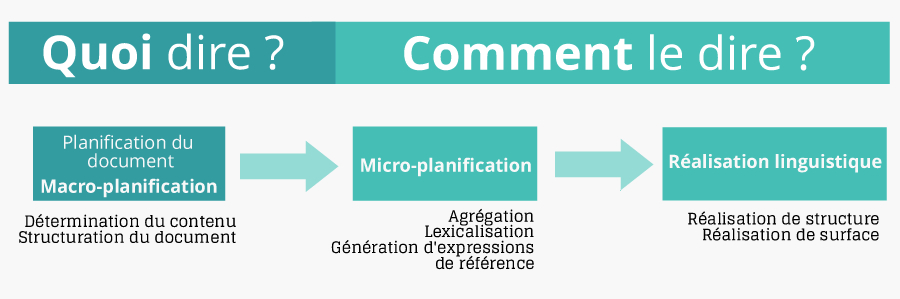
Un processus standardisé en matière de GAT se découpe en trois temps : la planification du document (document planning ou macro-planning), la micro planification (macro-planning) et la réalisation de surface. Ces moments correspondent aux deux étapes formulées dans les questions ”Quoi dire ?” et ”Comment le dire ?”. Ponton note que les étapes de cette architecture en pipe-line ”n’interviennent pas forcément de façon linéaire dans le processus de génération et qu’elles sont souvent en interaction l’une avec l’autre. De plus, ces étapes ne coexistent pas forcément de façon si distincte dans les systèmes. Cependant, ces deux modules parfois ’théoriques’ et dont la frontière est souvent délicate à définir (par exemple, l’organisation des informations relève-t-elle du ’Quoi dire ?’ ou du ’Comment le dire ?’), permettent de manière générale de bien appréhender le déroulement et les difficultés liées à la production d’un texte en langue naturelle”[9].
Références
[1] Reiter Ehud et Dale Robert. Building Natural Language Generation Systems.
Cambridge University Press, 2000
[2] http ://www.britannica.com/EBchecked/topic/198506/expert-system
[3] Krahmer Emiel et Theune Mariet. Empirical Methods in Natural Language Generation : Data-oriented Methods and Empirical Evaluation. LNCS sublibrary : Artifical intelligence. Springer, 2010
[4] Danlos Laurence. Génération automatique de textes en langue naturelle. Linx. Texte et ordinateur. Les Mutations du Lire-Ecrire., hors-série(4) :197–214, 1991.
[5] Danlos Laurence, idem
[6] Balicco Laurence, Ben-Ali Salaheddine, Ponton Claude, et Pouchot Stéphanie. Apports de la generation automatique de textes en langue naturelle a la recherche d’information. In Proceedings of the Annual Conference of CAIS/Actes du congrès annuel de l’ACSI, 2013
[7] Dalianis Hercules. Aggregation in natural language generation. Computational Intelligence, 15(4) :384–414, 1999
[8] Danlos Laurence et Pierrel Jean-Marie (coordonné par). Ingénierie des langues. in IC2 : information, commande, communication. Hermès Science publications, 2000.
[9] Ponton Claude. Génération automatique de textes : 30 ans de réalisations. Géné-ration Automatique de Textes (GAT’97), 1997




