Expliquer ce qu’est l’IA à des étudiantes et étudiants en journalisme implique de rendre accessibles des concepts mathématiques souvent complexes et abstraits. Cette simplification est essentielle, car elle permet de mieux comprendre à la fois les possibilités et les limites de l’IA, tout en contribuant à la littératie numérique et à la compréhension critique des technologies. Les réseaux neuronaux, qui sont à la base de nombreuses applications d’IA, y compris les grands modèles de langage, jouent un rôle central dans cette compréhension.
Un réseau neuronal fonctionne comme une calculatrice très sophistiquée – ou, plus précisément, comme une machine capable de repérer des motifs dans les données. Une couche reconnaît des formes simples, la suivante les combine, et la dernière prend une décision.
Pour apprendre, un réseau est entraîné sur un jeu de données composé d’exemples déjà étiquetés, qui servent de référence pour corriger ses erreurs. Un réseau neuronal apprend donc les régularités présentes dans les données qu’on lui fournit. Si ces données sont biaisées, il reproduira ces biais. Plus généralement, le comportement du réseau dépend entièrement des données sur lesquelles il a été entraîné : si elles sont partielles, biaisées ou mal étiquetées, ses erreurs viendront de là.
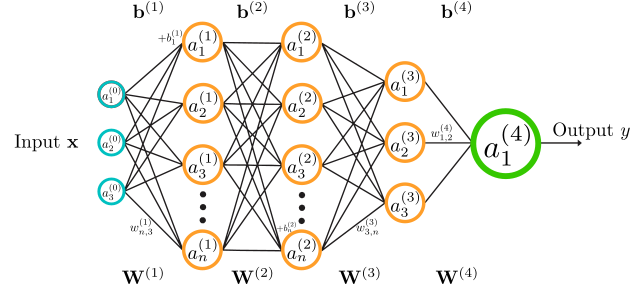
Un réseau neuronal comporte une couche d’entrée, une couche de sortie et au moins une couche cachée. Chaque couche contient un certain nombre de neurones. Dans les couches cachées, chaque neurone possède un biais : une couche avec X neurones possède donc X biais. Dans le cas de la classification d’une image, par exemple :
– la première couche observe des détails bruts (contours, nuances),
– la suivante combine ces informations (formes, textures),
– et les dernières couches prennent une décision (chat / pas chat).
Pour comprendre le nombre de paramètres, il suffit d’observer les connexions : entre deux couches, chaque neurone de la première est relié à tous les neurones de la suivante.
On obtient donc :
• X × Y poids, si la première couche contient X neurones et la seconde Y,
• + Y biais, un par neurone de la couche suivante.
L’ensemble de ces poids et biais constitue les paramètres du réseau.
Avoir beaucoup de paramètres permet au réseau de modéliser des phénomènes complexes, mais cela nécessite aussi beaucoup de données pour éviter l’overfitting, un phénomène où le modèle apprend tellement bien de ses données d’entraînement qu’il ne parvient plus à généraliser sur de nouveaux exemples.
Le réseau effectue d’abord un calcul et produit une sortie. Il compare cette sortie à la valeur réelle pour obtenir une loss, c’est-à-dire une mesure numérique de l’erreur. Pour les tâches où l’on doit prédire un nombre, on utilise souvent la MSE (Mean Squared Error). Pour les tâches de classification, comme déterminer si une image contient un chat, on utilise plutôt la cross-entropy, qui mesure à la fois l’erreur et le degré de certitude du modèle.
Les modèles ne donnent pas une “réponse”, mais une probabilité. C’est fondamental pour comprendre ce qu’est une prédiction d’IA. Par exemple, un réseau ne dit pas “c’est un chat” mais “il y a 92 % de chances que ce soit un chat”. Les décisions sont donc probabilistes.
Lors de la première itération, les poids sont choisis au hasard : les prédictions sont donc mauvaises et la loss est généralement élevée. Mais cette loss indique dans quelle direction le réseau doit ajuster ses paramètres. Plus l’erreur est grande, plus les corrections initiales sont importantes.
Pour réduire cette erreur, le système applique la descente de gradient, un algorithme qui ajuste progressivement les paramètres pour rapprocher la prédiction de la vérité. Le mécanisme qui calcule précisément comment chaque poids doit être modifié s’appelle la backpropagation. En répétant ce processus sur un grand nombre d’exemples, le réseau s’améliore progressivement : il apprend.
Après chaque calcul, une fonction d’activation permet au réseau de déterminer si un neurone doit s’activer fortement, faiblement, ou pas du tout. Elle introduit une forme de « décision » dans le réseau et évite qu’il ne se comporte comme une simple équation linéaire.
Cela étant, un réseau neuronal excelle sur les tâches pour lesquelles il a été entraîné, mais il peut se tromper complètement dès qu’il sort de son domaine.
A quoi sert un réseau neuronal dans le journalisme ?
– transcrire automatiquement des interviews,
– analyser des images (ex : fact-checking),
– recommander du contenu,
– détecter des deepfakes,
– classer des documents.



