Le projet Iwacu Open Data, né dans le giron du groupe de presse Iwacu au Burundi, constitue un exemple de ce qu’il est possible de faire en tirant parti d’outils technologiques qui ne sont pas inaccessibles tout en jouant sur leur complémentarité. Ou comment créer et gérer un portail open data sans grands moyens mais avec des idées.
En janvier 2010, un dollar américain s’échangeait contre 1.233 Francs Bu au marché officiel. Huit ans plus tard, il en vaut 1.785. Quant au prix de la bière, boisson nationale par excellence, il ne cesse d’augmenter, passant du simple au double en une dizaine d’années. Si l’on regarde la production de café vert au Burundi, elle évolue en dents de scie depuis le début de la dernière décennie et malgré des prévisions optimistes pour 2018, elles sont loin des records engrangés au milieu des années 2000. Depuis 2014, la population pénitentiaire ne cesse d’augmenter : +48% comparé à 2018. Toutes ces informations, traitées par les rédactions du groupe de presse Iwacu, un des derniers médias indépendants en activité au Burundi depuis la destruction de plusieurs médias en 2015, ont un point commun : elles résultent d’une analyse de données. Si les données sont des faits bruts, ceux-ci ne prennent sens qu’à partir du moment où ils font l’objet d’un traitement journalistique. Mais chez Iwacu, on expose les faits tels qu’ils sont : toutes les données récoltées par la rédaction se trouvent aussi en accès libre sur un portail open data unique en son genre en Afrique.
Des idées… mais peu de moyens
Cette aventure, qui a débuté il y a bientôt deux ans, est née au détour d’une conversation avec Antoine Kaburahe, directeur et fondateur d’Iwacu. Il revenait d’une de ces conférences dédiées au journalisme dans lesquelles le datajournalisme est un genre particulièrement célébré. Comment impulser cet esprit data dans ses médias en ligne et imprimés ? S’il existe bien des données sur le Burundi, celles-ci sont disséminées sur les pages web de portails opens data ou d’ONG. Il faut parfois bien fouiller pour les trouver. Les journalistes de la rédaction travaillent déjà avec des données, mais ils ne font rien de ce qu’ils ont récolté après que leur article soit publié. Au Burundi, comme dans une majeure partie du continent, la culture politique n’est pas vraiment celle de la transparence. Ces constats ont nourri le projet : pourquoi ne pas rassembler toutes ces données en un seul endroit et les mettre non seulement à disposition des journalistes, mais aussi de tous les acteurs intéressés par la vie économique, politique, sociale et culturelle de ce petit pays d’Afrique de l’Est ?
L’idée était un peu folle. Il n’y avait pas de budget disponible, pas de journalistes spécifiquement formés « data », mais il y avait l’envie de le faire et une « mama web » motivée. Elvis Mugisha, qui a fait ses débuts au service graphique d’Iwacu avant de devenir éditeur web, présentait un profil intéressant. Intéressé par la chose chiffrée et toujours partant pour apprendre, il a fallu le former pour assurer une mission de data manager. On a travaillé sur la récolte de données puis sur leur nettoyage. On a travaillé sur les formats, sur les outils de datavisualisation, sur la manière de gérer ses données et ses métadonnées… Il a fallu établir un plan d’action, mais aussi de management, tenant compte des caractéristiques neuves inhérentes au projet, mais aussi de paramètres techniques qui ne devaient pas être trop complexes pour bien être bien compris… et pris en mains : de Bujumbura à Bruxelles, ce sont plus de 9.500 kilomètres !
Sous le capot du portail
La conception du portail s’est inspirée d’une étude de l’existant en matière de portail open data. Huit catégories ont été définies, tenant compte des particularités du Burundi. L’interface s’est inspirée des bonnes pratiques et elle a été conçue pour WordPress, un système de gestion de contenus déjà bien connu chez Iwacu. Le thème a été développé sur mesure pour répondre de la manière la plus précise aux besoins de gestion. Il intègre les dimensions relatives aux métadonnées, dont l’utilisation du standard Dublin Core, ainsi que toutes les contraintes de publication définies en amont. Chaque jeu de données comporte un titre, une description, des métadonnées et il est téléchargeable au format CSV (le couteau suisse du format ouvert), mais aussi en XLS (puisque les jeux sont d’abord organisés en Excel avant d’être convertis). Les métadonnées sont également téléchargeables mais dans deux formats ouverts (CSV et DCXML pour le Dublin Core) Highcharts a été choisi comme outil de datavisualisation, mais dans sa version cloud car elle est pratique, rapide (ne nécessitant pas de codage) et les dataviz qui y sont stockées peuvent être intégrées autant dans le portail open data que sur le site d’Iwacu.
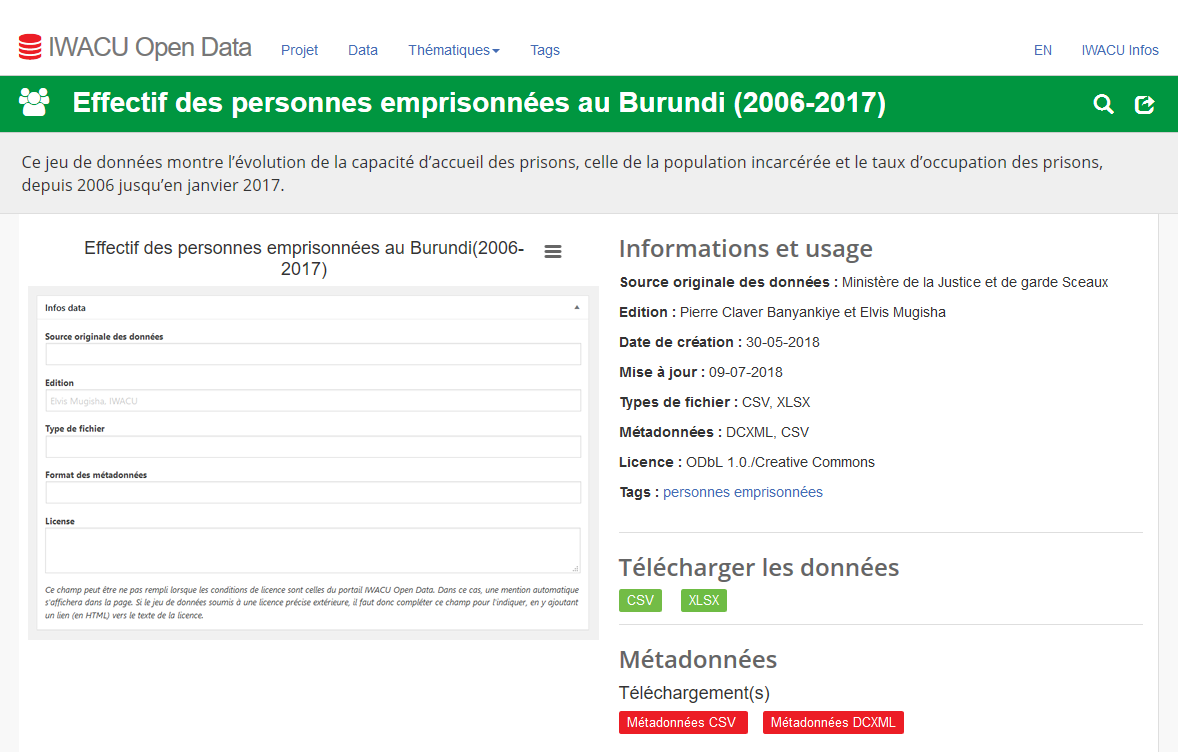
Optimisations sémantiques
Dans une base documentaire, la manière dont le portail a d’emblée été envisagé, il faut pouvoir trouver ce que l’on cherche et l’option d’une recherche « full texte » n’est pas toujours la plus pertinente en termes de bruit (les résultats que l’on obtient et que l’on ne devrait pas obtenir) ou de silence (les résultats que l’on devrait obtenir et que l’on n’obtient pas). La seule taxonomie des catégories apparaissait comme insuffisante, en raison de leur caractère très général. L’option a été de se servir du thésaurus Media Topics de l’International Press and Telecommunication Council (IPTC) destiné aux médias, de le traduire en français et de l’adapter au contexte Burundais.
L’apport du documentaliste d’Iwacu a permis de le finaliser. De manière à ce qu’il puisse servir à tous les projets en ligne d’Iwacu, il a été développé sur Tematres, une plateforme open source dédiée à la gestion de vocabulaires contrôlés.
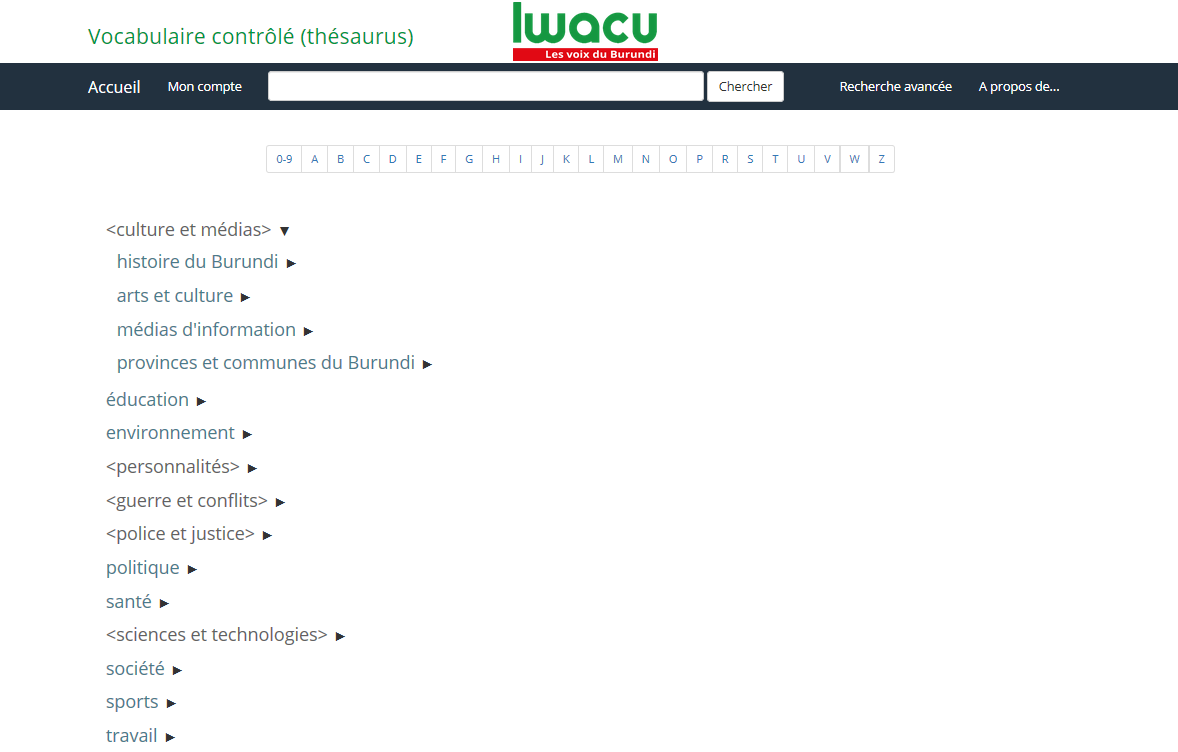
Le gros avantage de la formule, outre sa simplicité d’utilisation, n’est pas seulement de proposer des linked data pour chaque terme du thésaurus : c’est aussi celui de pouvoir exporter l’ensemble du thésaurus au format RDF. Celui-ci est directement mis en relation avec l’installation WordPress via le plugin Pool Party Thesaurus, qui génère automatiquement un classement par ordre alphabétique. Le plan de classement du portail est aussi accessible sur un mode visuel interactif.
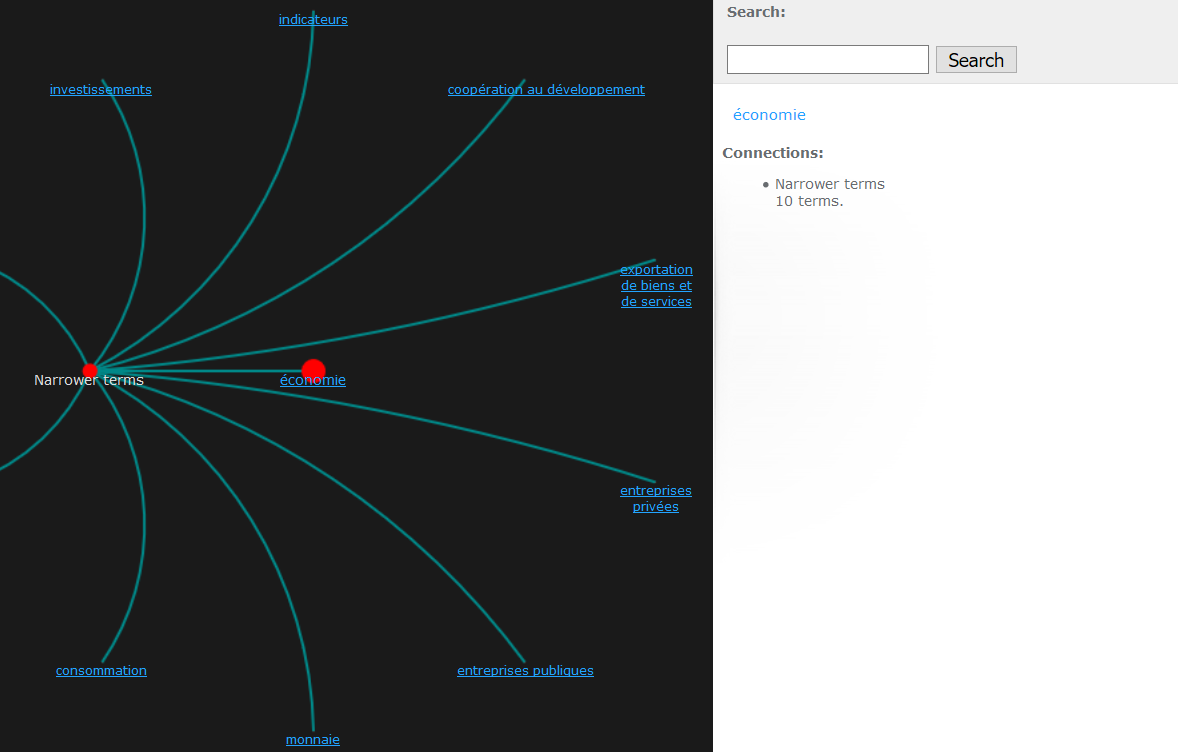
Au rayon des plugins, l’option a été de développer du « maison » un maximum et de se servir du minimum profitable au portail : Dublin Core Metadata (pour ne pas réinventer la roue), Relevanssi (pour améliorer les performances de recherche), WP-Linked Data (pour partager les contenus dans une version linked data) et Schema (pour ajouter une couche sémantique supplémentaire au portail).
La vie du portail
Deux ans plus tard, le système est resté aussi robuste qu’à ses débuts… mais il fait l’objet d’une maintenance régulière. Proposé en deux langues, il compte aujourd’hui plus de 150 jeux de données en français et 130 en anglais. Les data sont gérées de manière autonome par un data manager qui a parcouru un bon bout de chemin déjà. A la rédaction, un datajournaliste a été engagé il y a quelques mois : Pierre Claver Banyankiye. Son profil n’est pas celui d’un journaliste mais celui d’un économiste habitué à jongler avec les chiffres… et à les analyser aussi. Les allers-retours entre le portail et les publications d’Iwacu sont de plus en plus nombreuses et des jeux de données « préparés maison » alimentent régulièrement la vie du portail.
Iwacu Open Data vit et évoluera certainement encore au cours des prochains mois. Ce sera le moment de l’évaluation afin de voir ce qui peut encore être amélioré et ce qu’il faudrait corriger. Les moyens financiers sont toujours aussi inexistants, mais les humains derrière le projet restent toujours aussi motivés par cette conjugaison inédite de datajournalisme et de citoyenneté.




