
En traitement automatique de la langue, les stop words sont des termes dont la signification manque de pertinence et qui peuvent donc être ignorés (Wilbur et Sirotkin, 1992 ; Lo et al, 2005). En d’autres mots, il s’agit d’un dictionnaire négatif (Fox, 1989). La classification et l’analyse de sentiments sur Twitter est généralement affectées par la nature bruyante des données des tweets : la suppression de mots vides permet donc d’en réduire le bruit (Saif et al., 2014). Toutefois, la suppression de certains termes sont susceptibles d’affecter les résultats d’une recherche. Il n’y a pas une seule méthode pour définir une liste de stop words, pas plus qu’aucune liste prédéfinie n’est plus utilisée qu’une autre. Toutefois, la Brown stop list (Fox, 1992) et la Van stoplist (Rijsbergen, 1979) sont considérés comme des standards (Saif et al., 2014).
Généralement, les pronoms, interjections et conjonctions peuvent être considérés comme des stop words. Etablir une liste de stop words doit à la fois tenir compte du domaine et de l’évolution de la langue. La fréquence des termes ou des tokens d’un corpus permet de travailler sur une liste de stop words, mais il n’y a pas de consensus à propos de celle à privilégier : les termes les plus fréquents doivent-il être exclus ou, au contraire, faut-il ignorer les termes à plus basse fréquence ? La meilleure méthode est celle qui permet d’aboutir aux meilleurs résultats (Fox, 1989 ; Saif et al., 2014).
De plus, une liste de stop words peut être très bien adaptée pour la génération de bigrammes et trigrammes, mais donnera lieu à de moins bonnes performances lorsqu’il s’agit de passer à l’analyse des sentiments. Pour cette raison, dans cette recherche, deux listes distinctes de stop words ont été établies, en vue d’optimiser l’adéquation à la tâche réalisée. En ce qui concerne le lexique n-grammes, les tokens présentant une fréquence inférieure ou égale à 5 ont été placés dans une liste spécifique. En effet, leur examen a permis de se rendre compte que ces faibles fréquences regroupaient des interjections, des chemins d’URL ainsi que des noms d’utilisateurs de Twitter. Cette liste ne peut être rendue publique pour des raisons d’anonymisation des utilisateurs de Twitter figurant dans le corpus de tweets.
Cette opération a été réalisée pour chacun des sous-corpus du corpus général. Une autre liste de stop words a été utilisée à la fois pour les lexiques n-grammes et pour l’analyse de sentiment, celle-ci se focalisant sur les termes vides de sens de la langue. Cet outil a permis de disposer d’une première base : https://countwordsfree.com/stopwords Son avantage est de proposer des listes prédéfinies en langue anglaise et en langue française, les deux langues du corpus. La V2 de cette liste de stop words (en langue anglaise) est disponible via la page Github du projet Mixology.
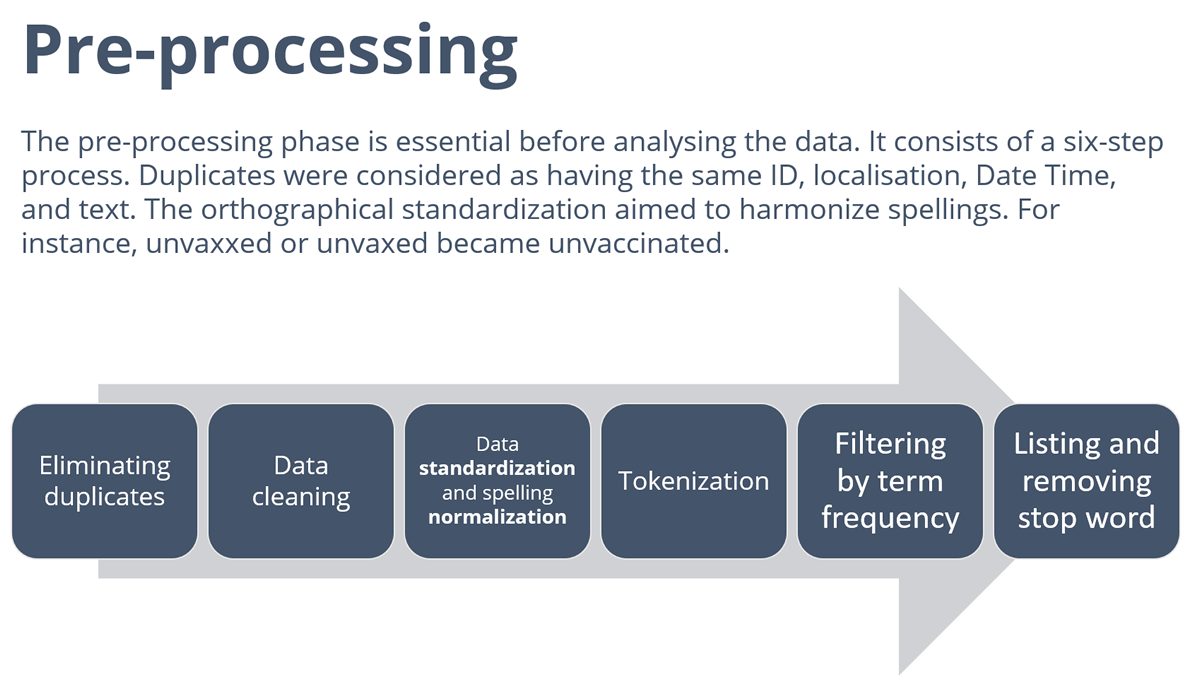
Toutes ces opérations ont été précédées par un important travail de nettoyage du corpus, celui-ci incluant l’élimination des doublons (mêmes identifiant, localisation, date et texte), et une harmonisation orthographique.
Tokenisation et stemming avec #RStats
Tokenisation : processus permettant de décomposer un document textuel en tokens, soit en mots uniques. Un token est donc une occurrence d’unigramme (Kuznetsov et Gurevych, 2018). Le package R tidytext propopse une fonctionnalité de tokenisation par unités de texte couramment utilisées (voir aussi Blog 8 pour les bigrammes et trigrammes).
Lemmatisation : analyse lexicale visant à regrouper tous les termes appartenant à une même famille (forme canonique, forme non fléchie d’un verbe, Turner et al.,2021). La lemmatisation est aussi appelée stemming ou racinisation. Le package R SnowballC s’appuie sur le la bibliothèque ‘libstemmer‘, laquelle implémente l’algorithme de Porter. Les langues actuellement prises en charge sont : danois, néerlandais, anglais, finnois, français, allemand, hongrois, italien, norvégien, portugais, roumain, russe, espagnol, suédois et turc.
Il existe également d’autres techniques de stemming possibles sous R, et le package tm permet aussi de réaliser des opérations de tokenisation et de stemming.
Références
Fox, C. (1992). Information retrieval data structures and algorithms. Lexical Analysis and Stoplists, pp. 102–130.
Fox, C. (1989, September). A stop list for general text. In Acm sigir forum (Vol. 24, No. 1-2, pp. 19-21). New York, NY, USA: ACM.
Kuznetsov, I., & Gurevych, I. (2018, August). From text to lexicon: Bridging the gap between word embeddings and lexical resources. In Proceedings of the 27th International Conference on Computational Linguistics (pp. 233-244).
Lo, R. , He, B., & Ounis, I. (2005, January). Automatically building a stopword list for an information retrieval system. In Journal on Digital Information Management: Special Issue on the 5th Dutch-Belgian Information Retrieval Workshop (DIR) (Vol. 5, pp. 17-24).
Turner, A. N., Challa, A. K., & Cooper, K. M. (2021). Student perceptions of authoring a publication stemming from a course-based undergraduate research experience (CURE). CBE—Life Sciences Education, 20(3), ar46.
Saif, H., Fernández, M., He, Y., & Alani, H. (2014). On stopwords, filtering and data sparsity for sentiment analysis of twitter.
van Rijsbergen, C. J., Information Retrieval, Butterworths, 1975
Wilbur, W. J., & Sirotkin, K. (1992). The automatic identification of stop words. Journal of information science, 18(1), 45-55.