
La modélisation thématique (topic modeling) est un type de modèle statistique utilisé pour découvrir des sujets ou concepts dans des documents (Schweinberger, 2021). Ceci s’inscrit dans le cadre plus large du distant reading (lecture à distance), un concept introduit par Moretti (2013), qui fait référence à l’analyse quantitative de données textuelles.
L’algorithme Latent Dirichlet Allocation (LDA) est l’un des plus populaires en matière de modélisation thématique d’un corpus de documents textuels. Il permet notamment d’évaluer la distribution des topics au sein du corpus, et il peut être utilisé autant pour la classification que pour la comparaison de documents.
Le LDA (Blei, 2003) fait partie de la famille des algorithmes d’apprentissage non-supervisé, c’est-à-dire qu’il ne nécessite aucune activité humaine d’annotation. Il s’agit d’un modèle probabiliste, s’appuyant sur ‘un modèle bayésien hiérarchique à trois niveaux, dans lequel chaque élément d’une collection est modélisé comme un mélange fini sur un ensemble sous-jacent de sujets. Chaque sujet est, en tour, modélisé comme un mélange infini sur un ensemble sous-jacent de probabilités de sujet’ (Blei, Ng and Jordan, 2003). Sur le plan empirique, la modélisation probabiliste aboutit généralement à de bons résultats et donne lieu à des décompositions sémantiques significatives.
Cet algorithme est inclus dans le package R topicmodels et il existe différentes manières de le programmer, les résultats pouvant différer selon les paramétrages utilisés et le nombre de topics souhaité (k). L’une d’entre elles consiste à utiliser l’échantillonnage de Gibbs, un algorithme qui échantillonne successivement des distributions conditionnelles convergentes. Il s’agit sans doute de la méthode la plus efficace, en ce sens qu’elle produit une plus grande variété dans la modélisation (Chang et al., 2009).
Modélisation 1 (LDA, Gibbs)
Modélisation 2 (LDA)
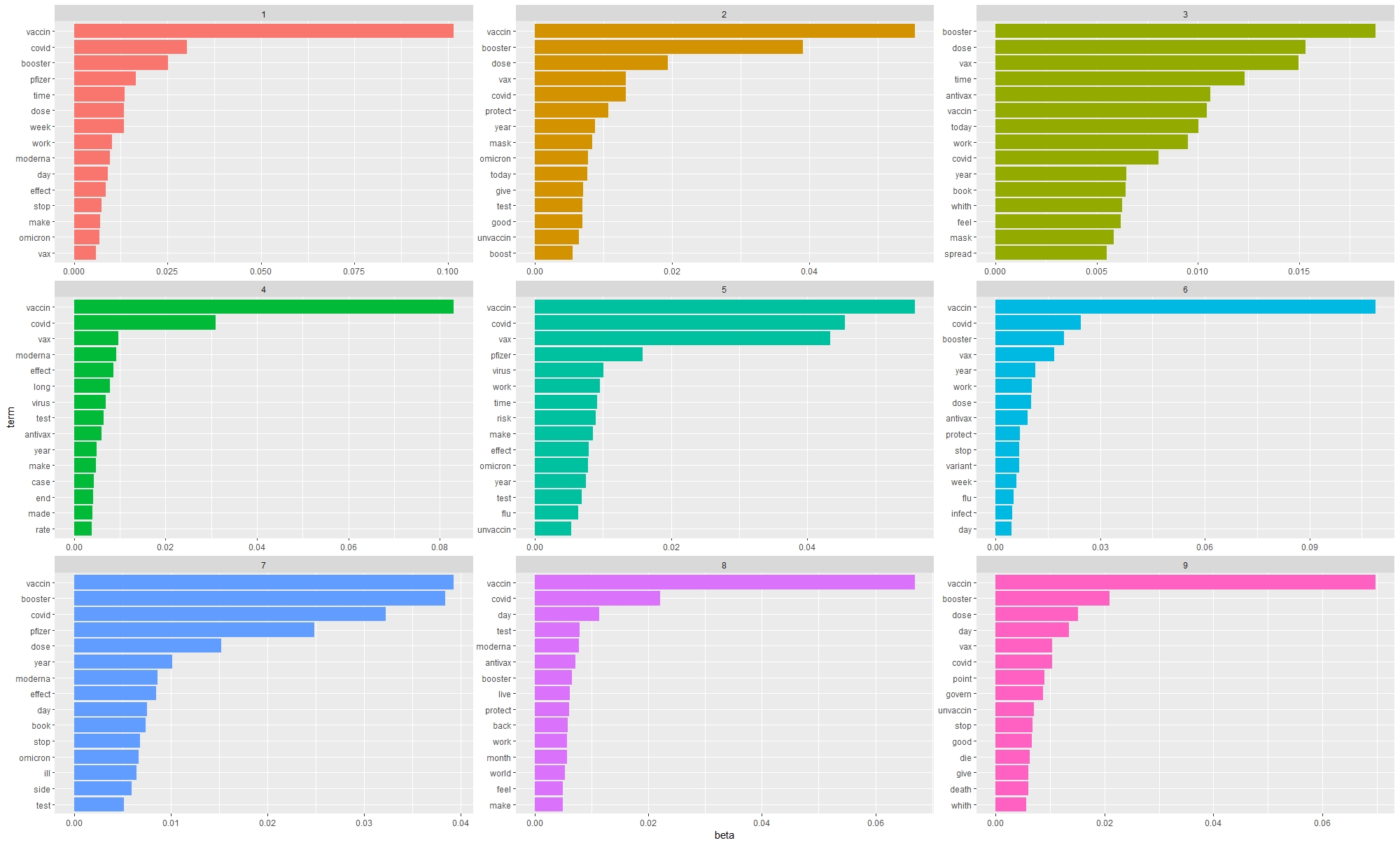
Les résultats obtenus avec l’algorithme LDA font référence aux thématiques du booster (troisième dose de vaccin), des mesures sanitaires (lockdown et pass vaccinal), des effets secondaires du vaccin, de la phase d’essai clinique des vaccins, de la propagation du variant omicron, des personnes non vaccinées ou ‘antivax’, du traitement médiatique de la crise sanitaire, des discours scientifique, et de la vaccination des enfants. Si ces thématiques rejoignent celles repérées lors de l’analyse lexicale (fréquence des termes, bigrammes et trigrammes), elles découvrent également des tendances qui n’avaient pas été observées jusqu’à présent.
Cette modélisation thématique se confirme à l’examen du modèle thématique corrélé (Correlated Topic Model, CTM), un modèle hiérarchique de collection de documents. Très gourmand en ressources, cet algorithme est limité à des modèles de petite taille (He et al., 2017). Toutefois, il présente l’intérêt d’être en mesure de modéliser la corrélation des sujets. Et, dans certains cas, il donne un meilleur ajustement que le LDA (Blei et Lafferty, 2006). Cela s’observe, en effet, dans cette troisième modélisation où les notions de doute et de confiance (envers les politiques, les vaccins, les sociétés pharmaceutiques, la science et les médias) apparaît en filigrane.
Modélisation 3 (CTM)
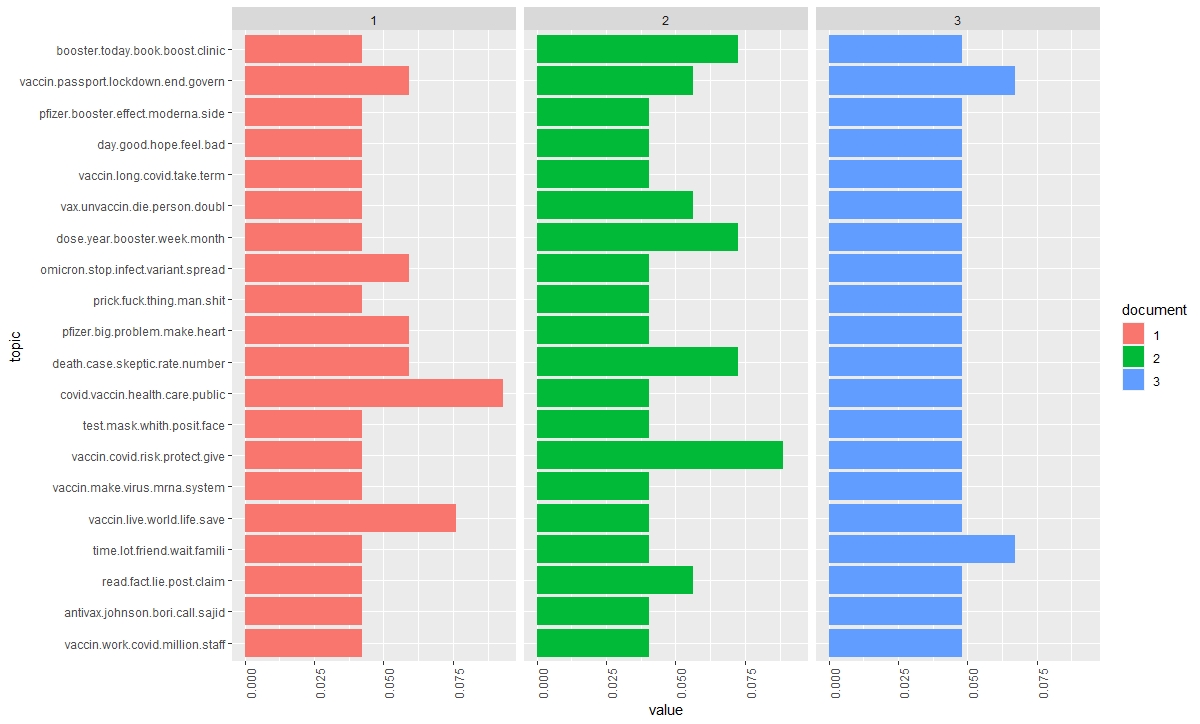
Cette analyse de la modélisation thématique du corpus ‘vaccins’ (langue anglaise) confirme les analyses précédentes, en ce sens que la crise n’est pas que sanitaire : elle est aussi politique et sociétale. C’est aussi une crise qui divise, entre pro et anti vaccins, lesquels sont critiqués pour leur stupidité, leur idiotie, leur complotisme. La question de la polarisation des discours se confirme donc à chaque niveau d’analyse de ce premier corpus de tweets (à suivre).
Références
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3:993-1022.
Blei, D., and Lafferty, J. (2006). Correlated topic models. Advances in neural information processing systems, 18:147.
Chang, J., Gerrish, S., Wang, C., Boyd-Graber, J. L., and Blei, D. M. (2009). Reading tea leaves: How humans interpret topic models. In Advances in neural information processing systems (pp. 288-296).
He, J., Hu, Z., Berg-Kirkpatrick, T., Huang, Y., and Xing, E. P. (2017, August). Efficient correlated topic modeling with topic embedding. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 225-233).
Hornik, K., and Grün, B. (2011). topicmodels: An R package for fitting topic models. Journal of statistical software, 40(13):1-30.
Moretti, F. (2013). Distant reading. Verso Books.
Schweinberger, M. (2021). Topic Modeling with R. Brisbane: The University of Queensland. URL: https://slcladal.github.io/topicmodels.html (Version 2021.11.24).
Silge, J., and David, R. (2017). Text Mining with R: A Tidy Approach. O’Reilly Media, Inc.
Ressources
- Latent Dirichlet Allocation Using Gibbs Sampling : https://ethen8181.github.io/machine-learning/clustering_old/topic_model/LDA.html
- Topic modeling using Latent Dirichlet Allocation(LDA) and Gibbs Sampling explained : https://medium.com/analytics-vidhya/topic-modeling-using-lda-and-gibbs-sampling-explained-49d49b3d1045
- Topic Modeling in R With tidytext and textmineR Package (Latent Dirichlet Allocation) : https://medium.com/swlh/topic-modeling-in-r-with-tidytext-and-textminer-package-latent-dirichlet-allocation-764f4483be73
- Topic modeling: https://www.rtextminer.com/articles/c_topic_modeling.html
- Topic Modeling of Surah Al-Kahfi : https://rpubs.com/azmanH/716181
- Intuitive Guide to Correlated Topic Models : https://towardsdatascience.com/intuitive-guide-to-correlated-topic-models-76d5baef03d3
- Package R ‘topicmodels’: https://cran.r-project.org/web/packages/topicmodels/topicmodels.pdf
- Package R ‘tm’: https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf