
La collecte des données du réseau social Twitter est réalisée via le package rtweet, disponible via RStudio. Cela suppose de disposer d’un compte « développeur » Twitter. Les premiers tests de récupération montrent une API un peu paresseuse, où il semblait difficile de récupérer beaucoup de contenus. Les premmières requêtes suivaient la nomenclature suivante :
Les trois requêtes réalisées étaient : vaccination OR vaccine / covid AND pass OR sanitary AND pass OR safe AND ticket / covid AND protest OR manifestation. Le pérmiètre géographique a été obtenu en traçant un cercle sur la carte de l’Europe.
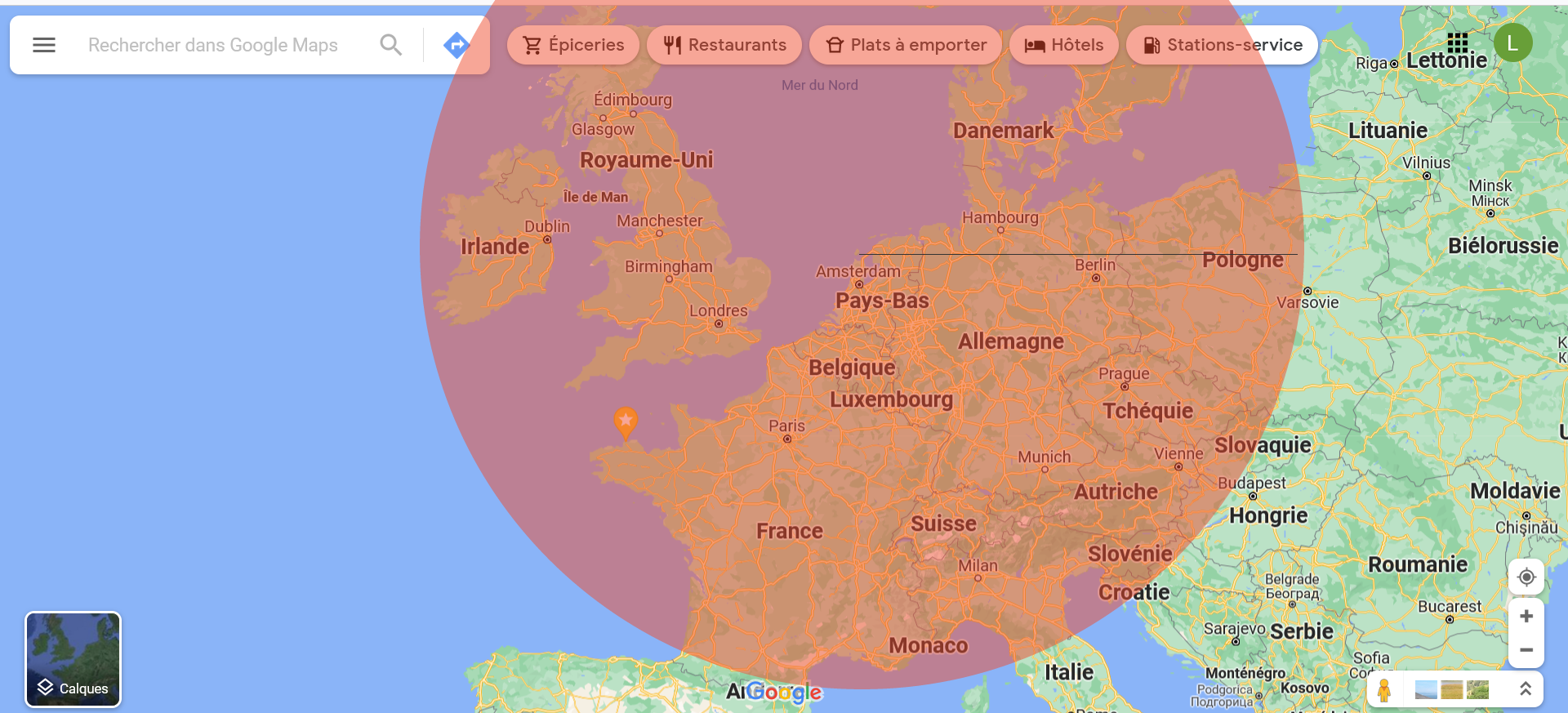
La distance d’un rayon est de 1.367 kilomètres, celui ayant été calculé entre deux points : de Juliandorp aux Pays-Bas (au centre) vers Rozan en Pologne. Malgré les premiers obstacles liés à la difficulté de faire aboutir les trois requêtes (blocage à 10%, 1% et 5% de récupération du contenu), cela a permis d’identifier les possibilités offertes en matière de récupération des variables (90 au total).
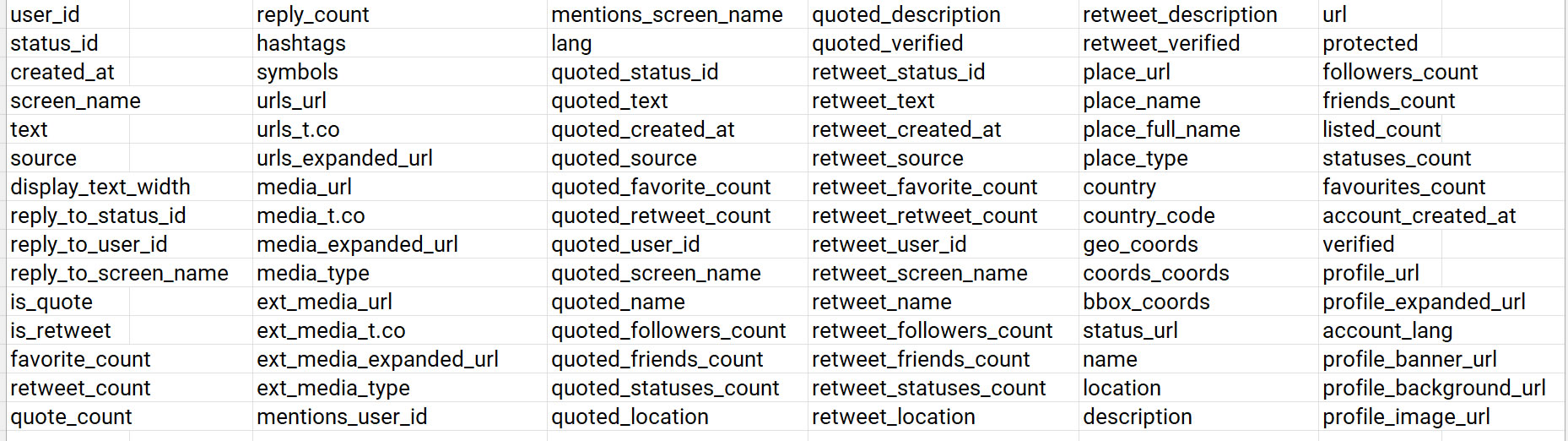
Toutes ces variables ne seront pas utilisées, et ceci également pour des raisons éthiques : 1) les utilisateurs ne sont pas informés de cette recherche ; 2) les utilisateurs ne peuvent faire valoir leur droit de retrait ; 3) le respect de la vie privée des utilisateurs est fondamental ; 4) cette recherche s’intéresse moins à qui le dit (même si cela est aussi intéressant sur le plan scientifique) qu’à ce qui est dit. Aussi, les variables retenues sont : text (contenu du tweet), lang (langue), location et country (localisation de l’utilisateur, pas forcément toujours renseignée).
Après avoir augmenté la mémoire de R et supprimé l’option de geocodage, la récupération des données s’est déroulée sans problème pour la première requête. Les requêtes trop complexes ont été simplifiées (voir ici les opérateurs booléens). Toutefois, big data ne veut pas dire bonne data. Retour à la case départ, en réfléchissant à la meilleure stratégie.