Au terme d’opérations de nettoyage et normalisation, le corpus relatif à la vaccination a été scindé en deux langues (français et anglais), en vue de procéder à une analyse distincte puis comparée. Le premier volet de ce premier corpus, en anglais, comporte 311.882 tweets. Les doublons ont été considérés comme présentant les mêmes identifiant, localisation, date et texte. Deux difficultés majeures se sont posées dans ce traitement : la définition du pays, pas toujours indiquée, sur base de localisation parfois fantaisistes (‘en enfer’, ‘à la campagne’, etc.) ; et une correction de la langue pas toujours optimale et/ou harmonisée. Par ailleurs, ce n’est pas parce que la langue indique « en » que le texte est bien rédigé en anglais. Dans ce corpus, il a fallu supprimer toutes les entrées en français, en néerlandais et en allemand. S’est ajouté un long travail d’annotation qui va servir de base pour des opérations automatisées qui seront appliquées aux autres parties du corpus (via un algorithme d’apprentissage supervisé). A noter que l’ensemble du corpus a été recueilli du 12 au 31 décembre, soit pendant une période de 20 jours.
Huit pays ont été sélectionnés pour l’analyse. Tous présentent un schéma similaire en matière de politique vaccinale, et où la question de l’obligation sectorialisée ou généralisée s’est invitée dans les débats d’une manière plus ou moins avancée : la France, la Belgique, les Pays-Bas, l’Allemagne, la Suisse, l’Autriche, le Grand-Duché de Luxembourg, l’Irlande et le Royaume-Uni. Bien que chaque utilisateurs de Twitter ne publie pas dans sa langue maternelle et que l’anglais soit une langue couramment utilisée, la répartition du nombre de tweets par pays montre un net une surreprésentation du Royaume-Uni (81,27%) par rapport aux autres pays, c’est là le biais de ce premier corpus qui compte 71.323 utilisateurs uniques.
L’examen des n-grammes (après tokenisation et intégration des ‘stop words’) a permis de réaliser une deuxième version du lexique, basé sur la fréquence des termes (n > 100), celle-ci étant influencée par les mots-clés utilisés lors du scraping avec le package R rtweet (voir Blog 3). Il a également permis de réaliser une deuxième version de la liste des ‘stop words’. Le lexique sera utilisé ultérieurement dans le cadre d’une analyse de sentiments. Ces nouvelles versions sont disponibles sur la page Github du projet.
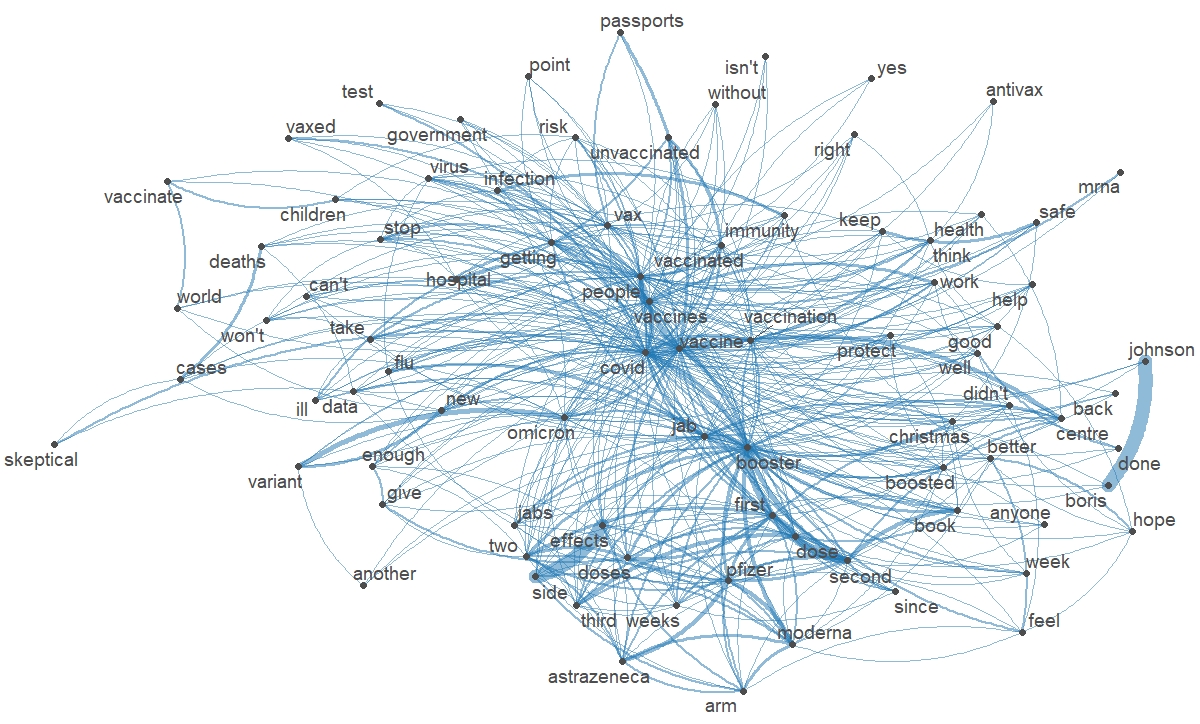
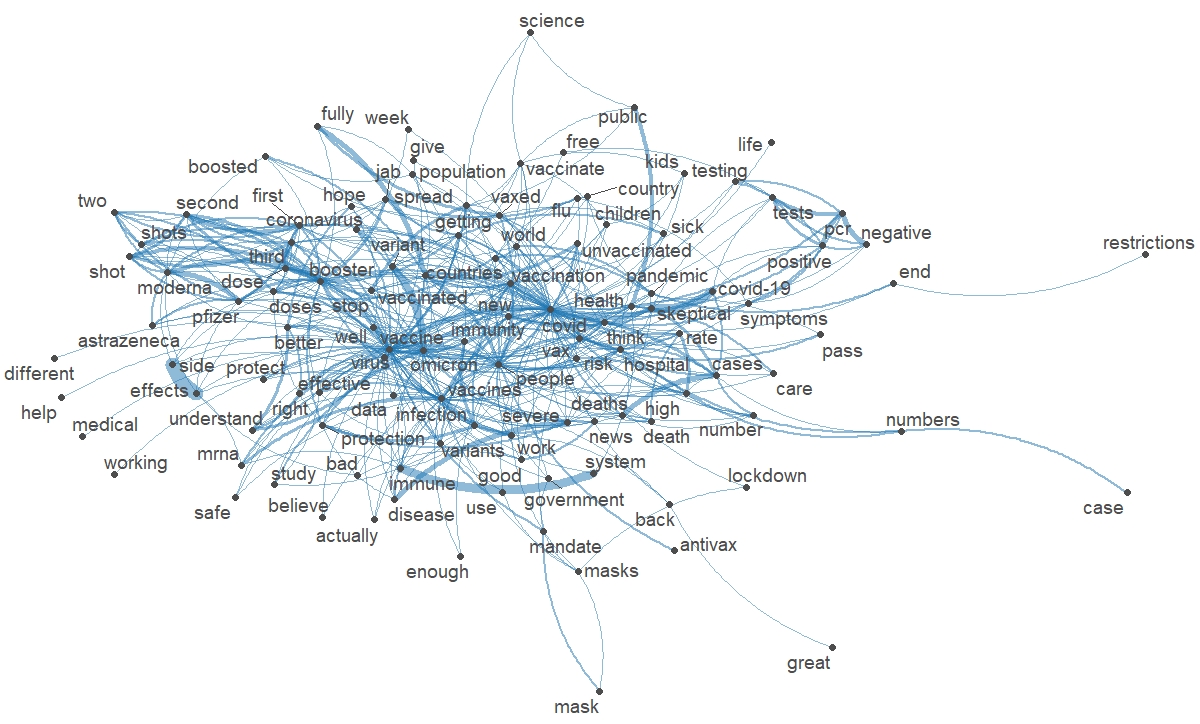
Le nuage de mot clés (réalisés avec le package R wordcloud) et les relations entre les termes (réalisées avec les packages R quanteda et quanteda.textplots) montrent que la préoccupation vaccinale est sanitaire (protection contre le virus vs craintes d’effets secondaires, implications ou conséquences du variant omicron, vaccination des enfants) mais aussi politique (mise en place d’un passeport vaccinal).

Ces représentations montrent également un certain scepticisme parmi certains utilisateurs de Twitter ainsi qu’un net clivage entre pro et anti vaccins (figure 1). Ces tendances sont confirmées lorsque les tweets provenant du Royaume Uni sont écartés du corpus, avec un accent davantage marqué sur le potentiel caractère obligatoire de la vaccination (en tout cas, en Allemagne) et les restrictions liées à la gestion politique de la pandémie (en France et aux Pays-Bas, en particulier). Ceci témoigne également de positions communes, en ce compris dans la polarisation des débats, entre les utilisateurs des huit pays sélectionnés dans le corpus (à suivre).