
La construction d’un dictionnaire spécialisé pour l’analyse de sentiment, incluant les termes les plus fréquemment utilisés dans le cadre de la crise Covid – dont beaucoup sont nouveaux – s’est déroulée en deux temps. En premier lieu, une liste des 4.000 termes les plus fréquents a été consignée dans une liste (après élimination des stop words, voir Blog 13).
Les dictionnaires General Inquirer, MPQA Subjectivity Lexicon, Loughran, Bing, NRC et Afinn ont été fusionnés dans une seconde liste (voir Blog 12). Les valeurs négatives du lexique Afinn sont devenues négatives, idem avec les valeurs positives et les valeurs 0 ont reçu une assignation ‘ambiguë’. En ce qui concerne les valeurs du dictionnaire Loughran, celles-ci ont été convertie comme suit : contraignant (négatif), litigieux (négatif), négatif, positif, superflu (ambigu), incertain (ambigu). Quant au dictionnaire NRC, la conversion a été réalisée comme suit : colère (négatif), peur (négatif), anticipation (positif), confiance (positif), surprise (ambigu), tristesse (négatif), joie (positif) et dégoût (négatif). Après élimination des doublons, l’ensemble des termes a été passé en revue manuellement, de manière à contrôler que des termes n’étaient pas classés dans deux catégories différentes : un terme catégorisé positif et négatif est soit devenu négatif, soit ambigu. Les termes étiquetés ambigus le sont restés dans la plupart des cas. Il s’agissait donc d’une évaluation humaine, par nature subjective, qui a porté sur 14.446 termes.
Dans un second temps, les termes extraits du lexique ‘Covid’ ont été comparés à la liste obtenue avec la fusion des six dictionnaires, en vue de leur assigner une catégorie positive, négative ou ambiguë. L’examen des bigrammes et des trigrammes a permis de comprendre comment ces termes étaient utilisés. De nombreux termes ont également été vérifiés via leur définition dans le dictionnaire. Ce travail a été assez long, mais il a permis de disposer d’une première version du lexique Covid qui comporte 3.847 termes, dont 1.812 sont positifs, 1.781 sont négatifs et 254 sont ambigus. La notion d’ambiguïté s’applique à des termes qui, selon leur contexte, peuvent être positifs ou négatifs. Celle-ci a été privilégiée au concept de ‘neutralité’, difficile à définir sans équivoques.
Il s’agit donc de la première version du Mixology Covid Lexicon, puisque réalisée à partir de la première partie du corpus en langue anglaise, relative à la vaccination (311.882 entrées). Le même travail est en cours pour la seconde partie de ce corpus, relative aux mesures politiques (confinement, pass sanitaire, protestions, soit 155.910 entrées). A ce dictionnaire s’ajoute la première version du dictionnaire Mixology Lexicon, qui consiste en la fusion des six dictionnaires cités précédemment avec le Mixology Covid Lexicon. Il comporte 16.531 observations catégorisées comme suit : 5.734 positifs, 9.662 négatifs et 1.135 ambigus.
Il reste encore beaucoup de travail à réaliser sur l’un et l’autre dictionnaire mais si vous souhaitez les tester, ils se trouvent en accès libre sur la page Github du projet.
Il existe également un autre corpus en langue anglaise, qui reprend l’ensemble des tweets des deux corpus précédents, mais dans lequel on retrouve aussi une série de tweets dont la localisation n’a pas pu être définie (paradis, enfer, au sud, etc.) ainsi que des tweets provenant plus largement de l’Europe de l’Ouest. Il totalise 796.769 entrées mais ceci est susceptible de varier au fur et à mesure des opérations d’élimination des doublons. Les corpus en langue française n’ont, quant à eux, pas encore été traités (ce traitement suivra la même logique que pour la langue anglaise).
Dans le prochain billet, j’aborderai les résultats des analyses de sentiment réalisées pour le corpus ‘vaccination’ en langue anglaise : comparaison entre différents dictionnaires, apport des deux nouveaux dictionnaires, influence (ou non) du nombre de termes étiquetés ‘positifs’ ou ‘négatifs’, et observations relatives à la qualité d’un dictionnaire, que ce soit en termes de précision, d’adéquation au contexte ou de quantité.
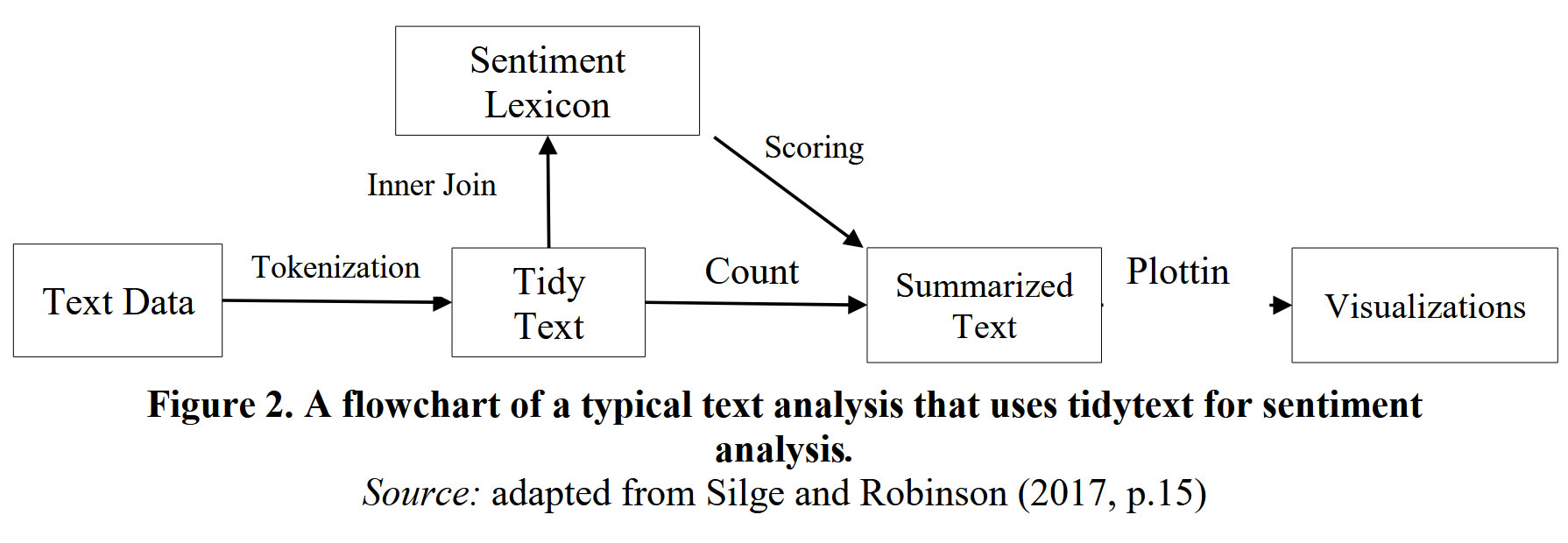
A noter que ces analyses ont été réalisées avec l’aide du package R tidytext, dont voici un schéma résumant le processus dans le cadre d’une analyse de sentiment.
Référence : Bogdan, M., & Borza, A. (2020). Big Data Analytics and Firm Performance: A Text Mining Approach. In Proceedings of the International Management Conference (Vol. 14, No. 1, pp. 549-560). Faculty of Management, Academy of Economic Studies, Bucharest, Romania.