La collecte du corpus, via l’API de Twitter, se déroule depuis neuf jours. A ce stade, les quatre axes de requêtes ont donné lieu à :
- Vaccination : 213.455 enregistrements (Europe de l’Ouest)
- Mesures (pass sanitaire et lockdown) : 150.718 enregistrements (Europe de l’Ouest)
- Mouvements de protestation : 107.671 enregistrements (Europe de l’Ouest)
- Général (tous les mots-clés) : 209.647 enregistrements (monde)
La préparation de l’analyse lexicale a débuté, en anglais, sur base du corpus « vaccination ».
Les packages R utilisés sont : tm, tidytext, wordcloud
Cela a nécessité un important travail de nettoyage et de préparation des données, qui est toujours en cours.
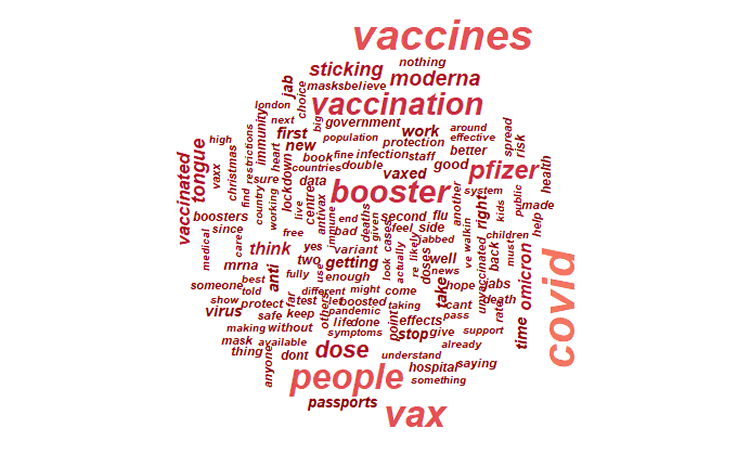
Toutefois, cette activité a permis d’identifier une première série de termes les plus fréquemment utilisés par les près de 50.000 utilisateurs uniques, ainsi qu’à une liste de « stop words » adaptée au corpus (fitness for use). Ces premières versions sont disponibles sur Github : https://github.com/laurence001/mixology
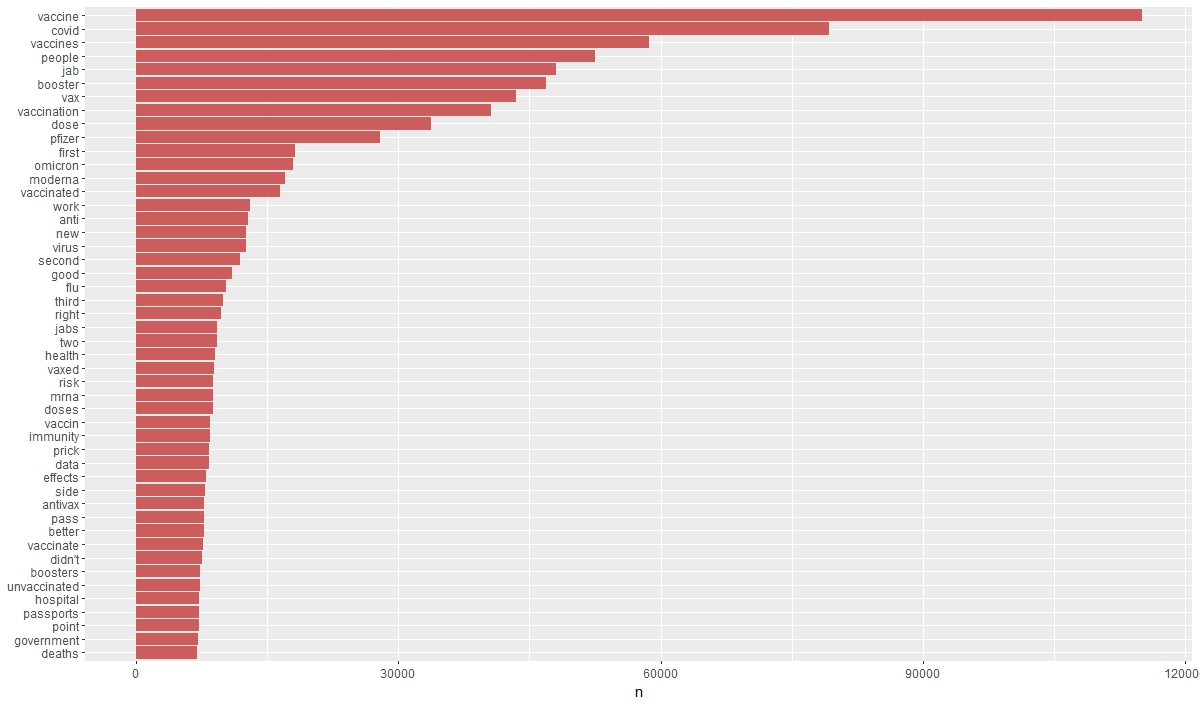
Sur le fond, cette préparation a permis d’identifier une polarisation des opinions au moins autour de quatre thématiques, en ce qui concerne le corpus « vaccination » : la santé (pro-vaccins, anti-vaccins, anti-vaccins ARN, rôle des big pharma), l’information (faits, information et désinformation), les mesures politiques (adhésion et résistance avec un vocabulaire parfois emprunté aux plus sombres moments de l’histoire pour mettre en exergue une forme d’autoritarisme, pro et anti-obligation vaccinale). Dans ces trois cas, la question de la confiance émerge d’ores et déjà. Ces constats seront à confirmer lors de la phase d’analyse proprement dite, laquelle tiendra également compte de la langue française.