In natural language processing, stop words are terms whose meaning lacks relevance and can therefore be ignored (Wilbur and Sirotkin, 1992; Lo et al., 2005). In other words, it is a negative dictionary (Fox, 1989). Sentiment classification and analysis on Twitter are generally affected by the noisy nature of tweet data: removing stop words can reduce noise (Saif et al., 2014). However, removing some terms may affect the results. There is no one way to define a list of stop words, and no predefined list is used more than another. However, the Brown stoplist (Fox, 1992) and the Van stoplist (Rijsbergen, 1979) are considered standards (Saif et al., 2014).
Generally, pronouns, interjections, and conjunctions can be considered stop words. Establishing a lstop words list must consider both the domain and the evolution of the language. The frequency of terms or tokens in a corpus makes it possible to work on a list of stop words, but there is no consensus about which one to favour: should the most frequent terms be excluded, or should the lower frequency terms be ignored? The best method is the one that leads to the best results (Fox, 1989; Saif et al., 2014).
Additionally, a stop words list may be well suited for generating bigrams and trigrams but will result in poorer performance in sentiment analysis. For this reason, in this research, two separate lists of stop words were established to optimize the adequacy of the task carried out. Regarding the n-gram lexicon, tokens with a frequency less than or equal to 5 have been placed in a specific list. Indeed, their examination made it possible to realize that these low frequencies grouped interjections, URL paths, and Twitter user names. This list cannot be made public for reasons of anonymization of Twitter users appearing in the corpus of tweets.
This operation was carried out for each sub-corpora of the general corpus. Another list of stop words has been used for both n-gram lexicons and sentiment analysis, focusing on meaningless terms. This tool has made it possible to have the first base : https://countwordsfree.com/stopwords Its advantage is to offer predefined lists in English and French, the two languages of the corpus. This list of stop words (V2, in the English language) is available via lthe Github page of the Mixology project.
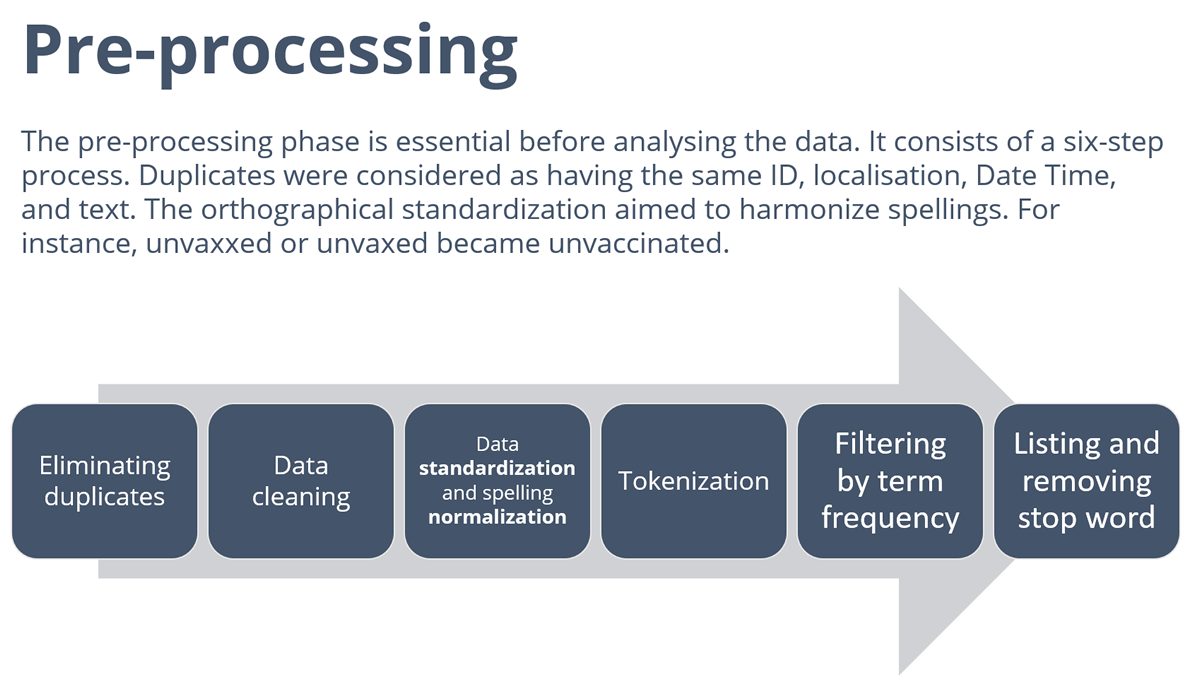
All these operations were prepared by a significant cleaning work of the corpus. It included removing duplicates (same identifier, location, date and text) and an orthographic harmonization.
Tokenization and stemming with #RStats
Tokenization: the process of breaking down a textual document into tokens or single words. Therefore, a token is an occurrence of a unigram (Kuznetsov and Gurevych, 2018). The tidytext R package offers a tokenization feature by commonly used text units (see Blog 8 for bigrams and trigrams).
Stemming: lexical analysis to group all the terms belonging to the same family (canonical form, uninflected form of a verb, Turner et al., 2021). The SnowballC R package relies on the ‘libstemmer‘ library, implementing Porter’s algorithm . Currently supported languages are Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish and Turkish.
There are also other possible stemming techniques in R, and the tm package also allows to perform tokenization and stemming operations.
References
Fox, C. (1992). Information retrieval data structures and algorithms. Lexical Analysis and Stoplists, pp. 102–130.
Fox, C. (1989, September). A stop list for general text. In Acm sigir forum (Vol. 24, No. 1-2, pp. 19-21). New York, NY, USA: ACM.
Kuznetsov, I., & Gurevych, I. (2018, August). From text to lexicon: Bridging the gap between word embeddings and lexical resources. In Proceedings of the 27th International Conference on Computational Linguistics (pp. 233-244).
Lo, R. , He, B., & Ounis, I. (2005, January). Automatically building a stopword list for an information retrieval system. In Journal on Digital Information Management: Special Issue on the 5th Dutch-Belgian Information Retrieval Workshop (DIR) (Vol. 5, pp. 17-24).
Turner, A. N., Challa, A. K., & Cooper, K. M. (2021). Student perceptions of authoring a publication stemming from a course-based undergraduate research experience (CURE). CBE—Life Sciences Education, 20(3), ar46.
Saif, H., Fernández, M., He, Y., & Alani, H. (2014). On stopwords, filtering and data sparsity for sentiment analysis of twitter.
van Rijsbergen, C. J., Information Retrieval, Butterworths, 1975
Wilbur, W. J., & Sirotkin, K. (1992). The automatic identification of stop words. Journal of information science, 18(1), 45-55.




