After several operations to clean and standardize the data, the Twitter corpus related to the vaccination campaign was split into two languages (French and English), intending to compare the analysis. In English, the first part of this first corpus contains 311,882 tweets. The duplicates were considered to have the same identifier, location, date, and text. Two significant difficulties arose in this treatment: the definition of the country, not always indicated, often made difficult (even impossible) because of fanciful locations (« in hell », « in the countryside », etc.), and wordings not always compliant with a correct language. This long annotation work will serve as a basis for automated operations applied to other corpus parts (via a supervised machine learning algorithm). Note that the whole corpus was collected from December 12 to 31 (20 days).
Eight west European countries have been selected for the analysis. They present a similar pattern in vaccine policy. Politics have also launched the debates around mandatory vaccination in a more or less advanced way: France, Belgium, the Netherlands, ‘Germany, Switzerland, Austria, Luxembourg, Ireland, and the United Kingdom. Although not every Twitter user posts in their native language and that English is a commonly used language, the breakdown of the number of tweets by country shows a clear over-representation of the UK (81.27%) compared to other countries. There is a total amount of 71,323 unique users.
The examination of the n-grams (after tokenization and integration of the ‘stop words’) made it possible to produce a second version of the Covid-lexicon, based on terms frequency (n> 100). Of course, the keywords used for scraping influence this list (see Blog 3). This second lexical round also produced a second version of the stop words list. The lexicon will be used later for sentiment analysis. These two new versions are available on the Github page of the project.
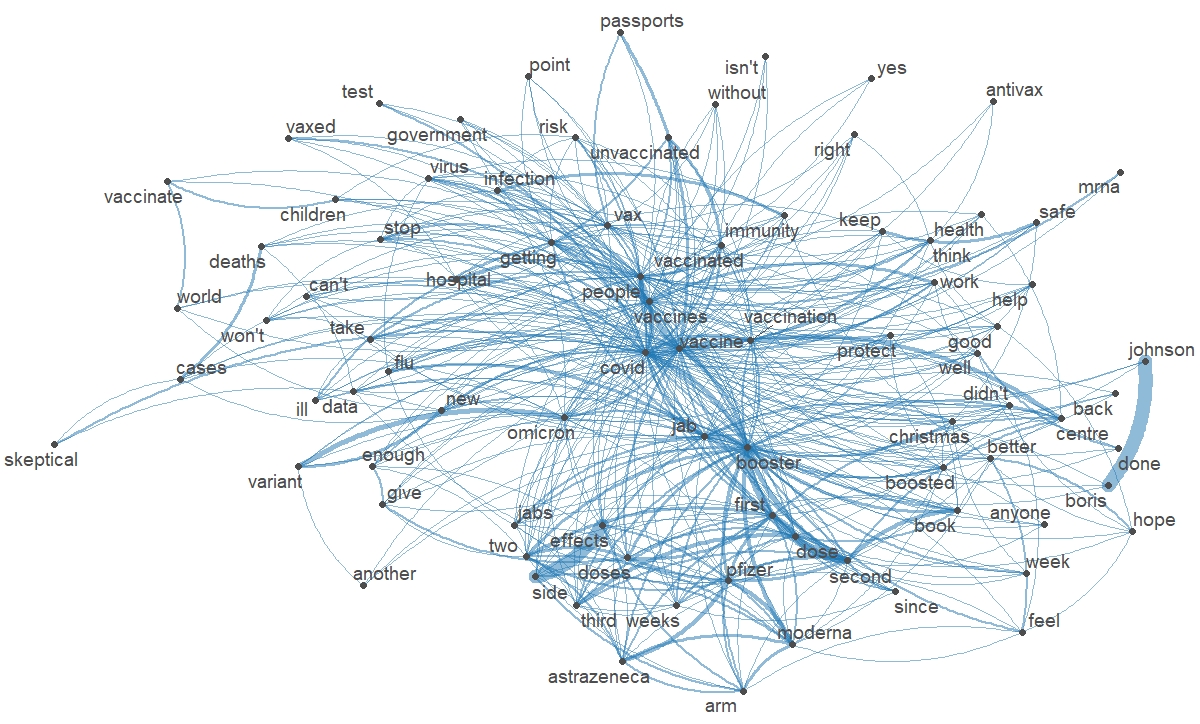
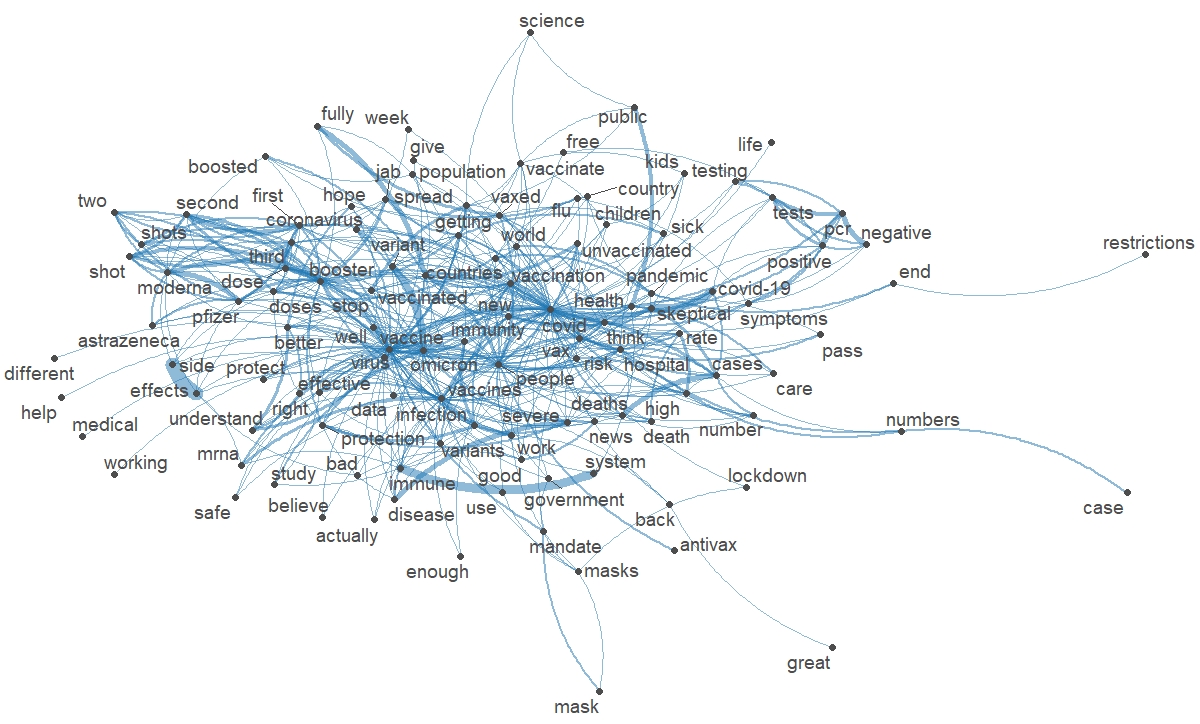
The word cloud (made with the R wordcloud package) and the relationships between the terms (made with the R packages quanteda and quanteda.textplots) show that the vaccination concerns are not only connected to health (protection against the virus vs. fear of side effects, implications or consequences of the omicron variant, childhood vaccination) but also to the politics (vaccination passport, lockdowns).

The data visualizations also show skepticism among some Twitter users and a clear divide between pro and antivaccine (Figure 1). These trends are confirmed when tweets from the UK are removed from the corpus, emphasizing compulsory vaccination (at least in Germany) and the politics of restrictions (in France and the Netherlands, in particular). This also testifies to common positions – the polarization of debates included – among the users of the eight countries selected in the corpus (to be continued).