Building a specialized dictionary for sentiment analysis, including the most frequently used terms in the context of the Covid crisis – many of which are very new – took place in two stages. First, a list of the 4,000 most frequent terms was recorded (after elimination of stop words, see Blog 13).
The dictionaries General Inquirer, MPQA Subjectivity Dictionaries Lexicon, Loughran, Bing, NRC, and Afinn, have been merged into a second list (see Blog 12). The negative values of the Afinn lexicon became negative, the same with the positive values, and the values 0 received an ‘ambiguous’ assignment. The values of the Loughran lexicon have been converted as follows: constraining (negative), contentious (negative), negative, positive, superfluous (ambiguous), uncertain (ambiguous). As for the NRC dictionary, the conversion was carried out as follows: anger (negative), fear (negative), anticipation (positive), confidence (positive), surprise (ambiguous), sadness (negative), joy (positive) and disgust (negative).
After removing duplicates, all the terms were reviewed manually to check which were not classified in two different categories: positive and negative were considered negative or ambiguous; and ambiguous terms remained so in most cases. It was a human evaluation, subjective in nature, which covered 14,446 terms.
In the second stage, I have compared the terms extracted from the ‘Covid’ lexicon with the merged list to assign them a positive, negative or ambiguous category. The examination of bigrams and trigrams provided information about how these terms were used in context. Many terms have also been verified via their definition in a English dictionary.
The work was quite long, but it made it possible to get a first version of the Mixology Covid Lexicon, which contains 3,847 terms, of which 1,812 are positive, 1,781 are negative, and 254 are ambiguous. The notion of ambiguity applies to terms that can be positive or negative depending on their context. It has been favoured over the concept of ‘neutrality’, which is challenging to define unequivocally. This version was produced on the first part of the corpus in English, relating to vaccination (311,882 entries). The same work is in progress for the second part of this corpus, related to political measures (lockdown, sanitary pass, protests, i.e. 155,910 entries).
This lexicon was merged with the six already merged dictionaries mentioned above to get the first version of the Mixology Lexicon.It includes 16,531 observations categorized as follows: 5,734 positive, 9,662 negative and 1,135 ambiguous. There is still much work to be done on both dictionaries, but if you want to test them, they are freely available on the project’s Github page.
There is also another corpus in English to be examined, which includes all the tweets from the two previous corpora, but in which we also find a series of tweets whose location could not be defined (heaven, hell, south, etc.) as well as tweets from Western Europe more broadly. It totals 796,769 entries, but this is likely to vary as the operations to remove duplicates progress.
In the next post, I will address the results of the sentiment analysis carried out for the ‘vaccination’ corpus in English: comparison between different dictionaries, the contribution of the Mixology Lexicon and the Mixology Covid Lexicon, the influence (or not) of the number of terms labelled ‘positive’ or ‘negative’, and observations about the quality of a dictionary, whether in terms of accuracy, contextual adequacy or quantity.
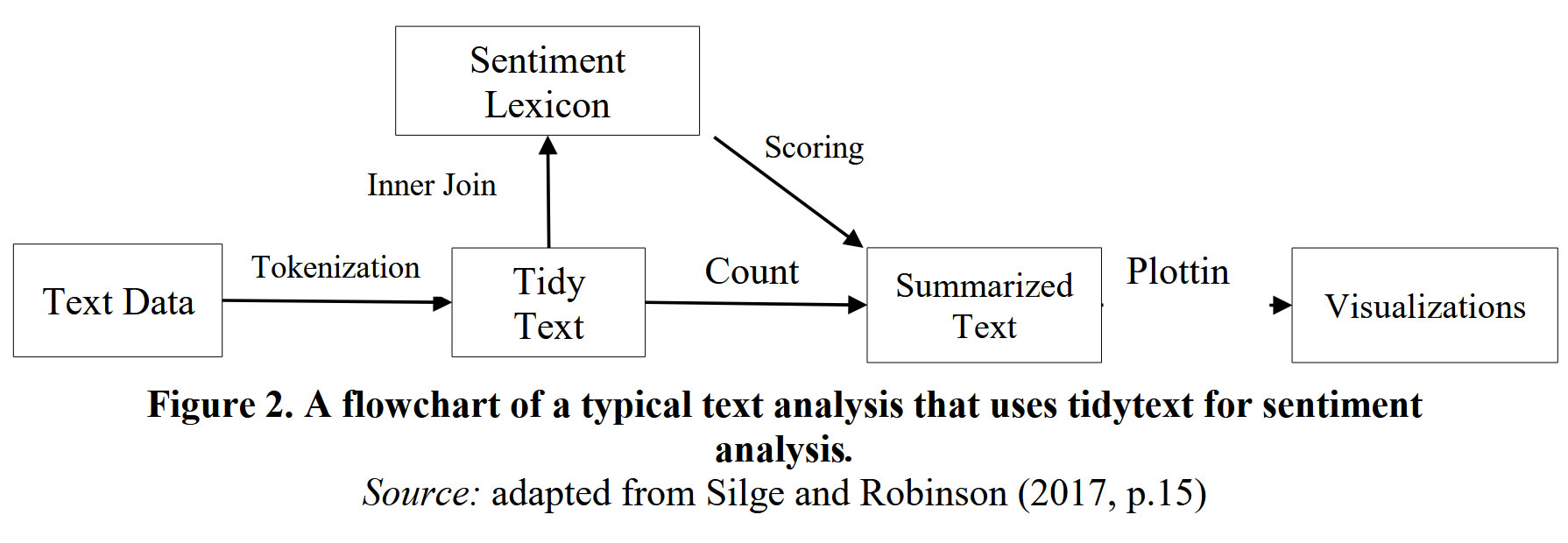
Note that these analyzes were performed with the R package tidytext, of which here is a diagram summarizing the process within the framework of sentiment analysis.
Reference : Bogdan, M., & Borza, A. (2020). Big Data Analytics and Firm Performance: A Text Mining Approach. In Proceedings of the International Management Conference (Vol. 14, No. 1, pp. 549-560). Faculty of Management, Academy of Economic Studies, Bucharest, Romania.




