The collection of the corpus has been going on for nine days. At this stage, the four queries axes have given rise to:
- Vaccination: 213,455 records (Western Europe)
- Measures (health pass and lockdown): 150,718 records (Western Europe)
- Protest movements: 107,671 records(Western Europe)
- General (all keywords): 209,647 records (world)
The preparation of the lexical analysis has started, in English, based on the « vaccination » corpus. The R packages used are: tm, tidytext, wordcloud
It has required significant data cleansing, which is still ongoing.
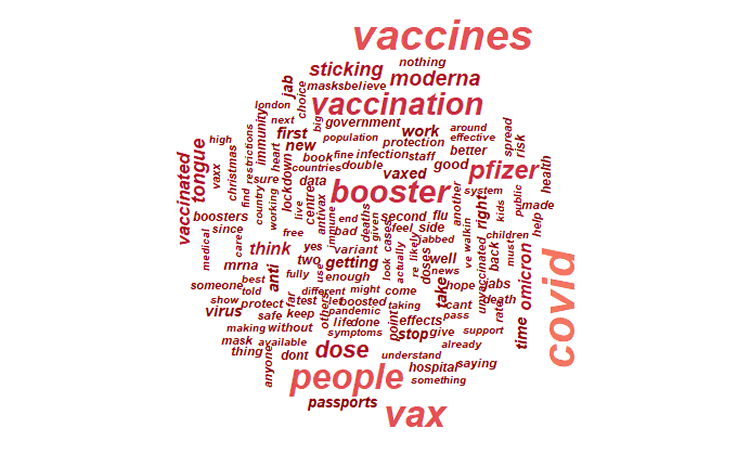
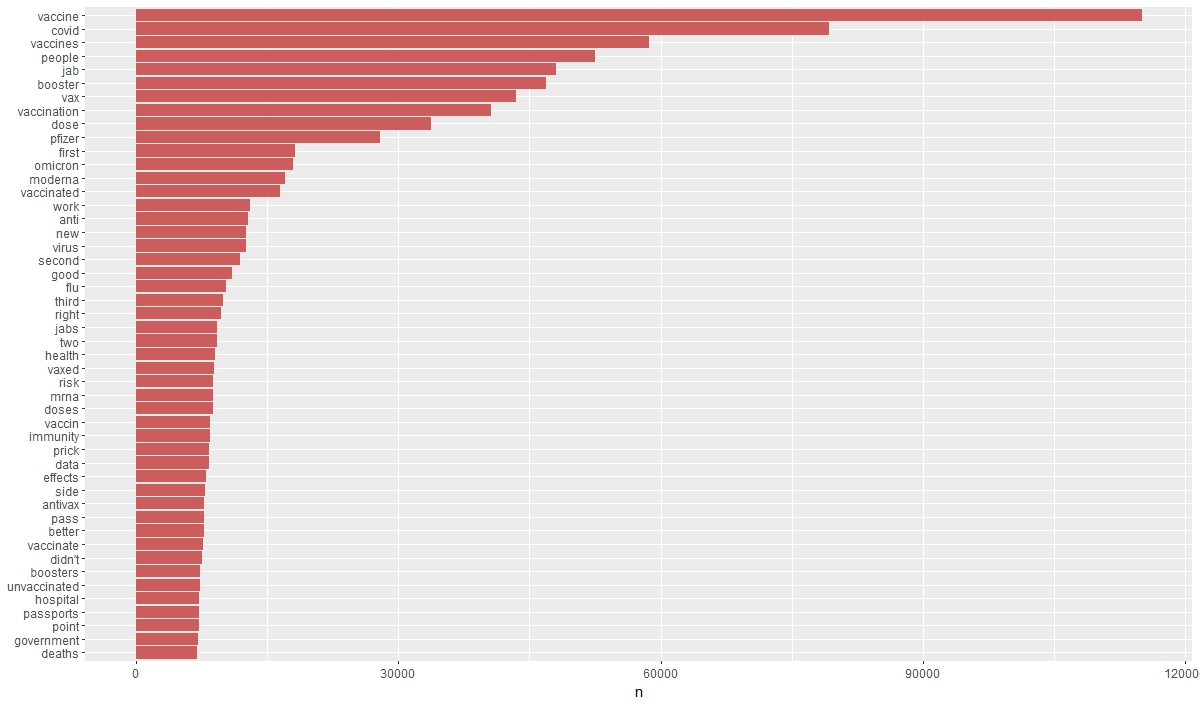
However, this activity made it possible to identify the first set of the most frequently used terms by the nearly 50,000 unique users and a list of stop words adapted to the corpus (according to the fitness for use principle). These first versions are available on Github: https://github.com/laurence001/mixology
This preparation also made it possible to identify a polarization of opinions at least around four topics related to the “vaccination” corpus: health (pro-vaccines, anti-vaccines, anti-mRNA vaccines, role of big pharma), information (facts and disinformation), political measures (adhesion and resistance with a vocabulary sometimes borrowed from the darkest moments of history to highlight a form of authoritarianism, pro, and anti-obligation vaccine). In all three cases, the question of trust is already emerging. These findings will need to be confirmed during the actual analysis phase, which will also consider the French language.