
The data gathering from the social network Twitter is carried out via the rtweet package (#Rstats). The first requests followed the following code:
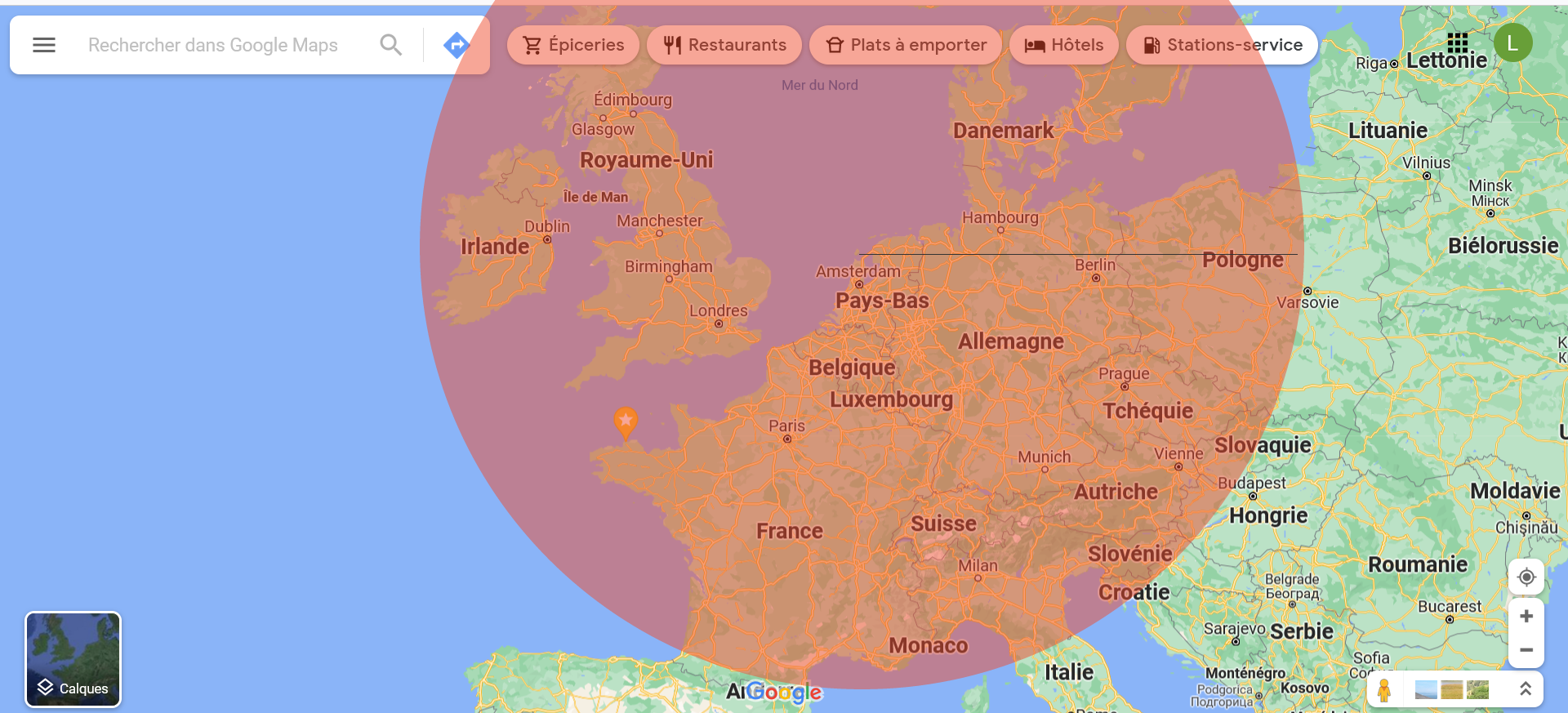
The geographical perimeter is calculated according to a radius of 1.367 kilometers from Juliandorp in the Netherlands (in the center) to Rozan in Poland. Despite the initial obstacles related to completing the requests (blocking at 10%, 1%, and 5% content retrieval), it was possible to identify 90 variables.
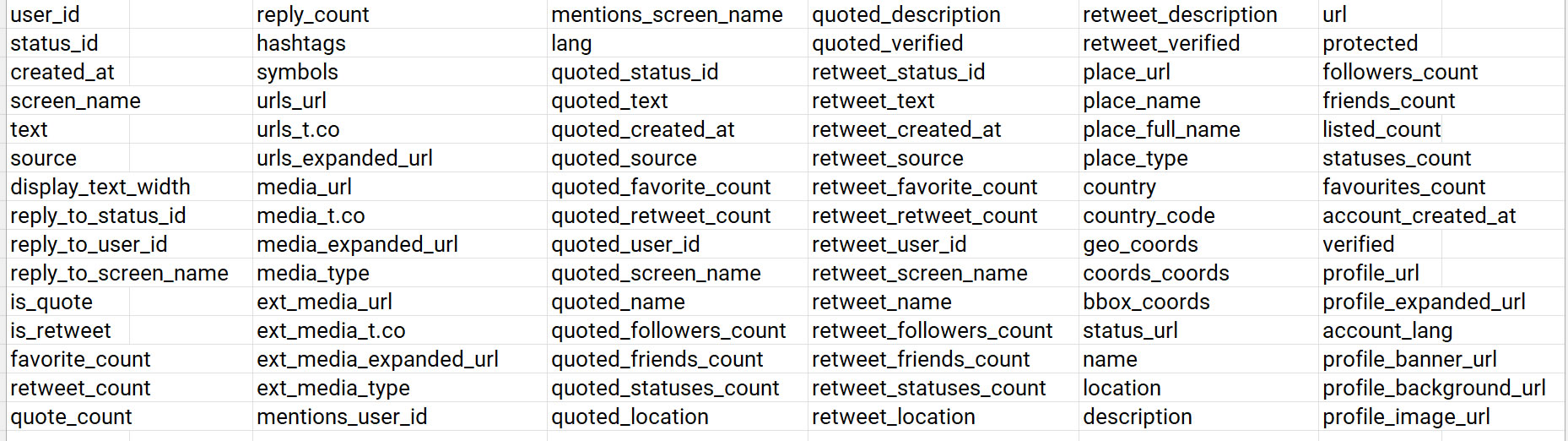
All these variables are not used in the constitution of the corpus, and this is also for ethical reasons:
- The users are not informed of this research.
- Users cannot exercise their right to withdraw.
- Respect for the privacy of users is fundamental.
- This research is less interested in who says it (even if it is also scientifically interesting) than what is said.
Also, the variables used are: text (the content of the tweet), lang (language), location, and country (location of the user, not necessarily always filled in), while user_id indicates the number of different users.